Análisis Léxico
Descripción
En el Analizador Léxico es donde empieza todo el proceso. Éste va leyendo de la entrada carácter a carácter hasta que detecta una cadena válida (lexema) o una cadena errónea. 
Una vez encontrado un lexema, hace algo más: le asigna un número llamado Token (al cual se le puede ver como el tipo o la categoría a la que pertenece el lexema).
El asociar este número a cada lexema facilita las fases posteriores. Si el léxico encuentra, por ejemplo, un print, en vez de que la siguiente fase tengan que estar mirando los cinco caracteres para descubrir de nuevo que se trata de este comando, el léxico ya entrega un número que representa dicha palabra reservada. Sería como comprimir la entrada reduciendo secuencias de caracteres a un sólo número.

No importa qué número se asocie a cada lexema, lo importante es que el léxico y resto de las fases se pongan de acuerdo en lo que significa cada número. Sin embargo, dado que sería engorroso trabajar con números, se definen constantes para simplificar su manejo.

Por tanto, en resumen, lo que hace el analizador léxico, visto como una caja negra, es:
- Entra una secuencia de caracteres.
- Salen parejas de (lexema, token).
Ejemplo
Dado el siguiente programa de entrada, a la derecha se muestra cual sería la salida del analizador léxico para dicha entrada (suponiendo que las constantes PRINT, PCOMA, etc. ya han sido definidas).
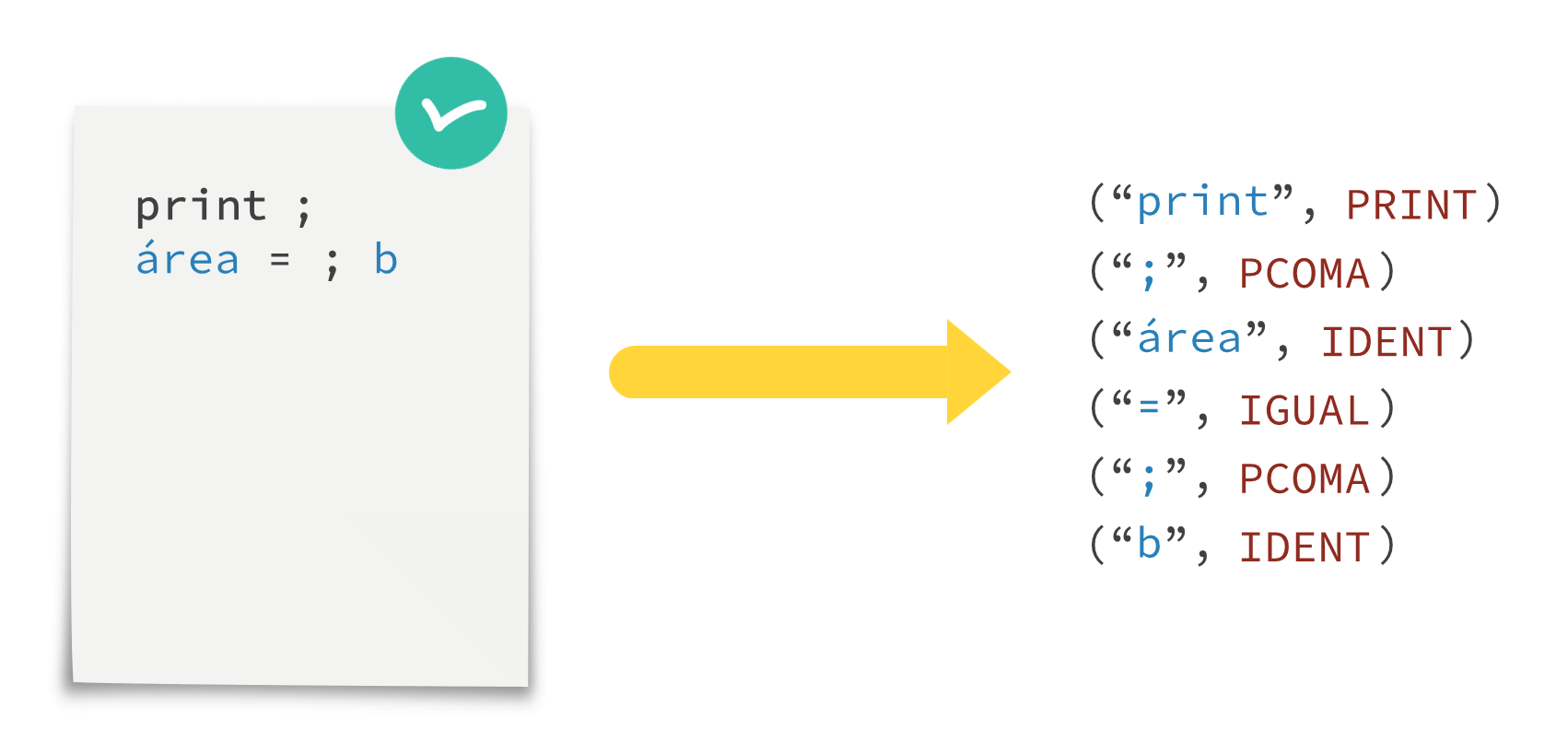
Nótese que el programa de la imagen anterior no sería válido ya que, por ejemplo, en la segunda línea de la entrada el punto y coma está antes que la b. Sin embargo, para el analizador léxico sería una entrada válida; no es su misión comprobar el orden en el que aparecen los lexemas. Se limita a comprobar que cada cadena, individualmente, sea válida. Será la siguiente fase la encargada de comprobar si los tokens están en el orden adecuado (y, en este caso, se detectará el error de que el punto de coma está antes que la b).