Análisis Semántico
Descripción
Llegados a este punto, se tienen lexemas válidos (comprobados por el analizador léxico) y en el orden adecuado (comprobado por el analizador sintáctico) ¿Qué más puede estar mal?
Supóngase la siguiente entrada:
print v[i] + 2;
Sin ver las sentencias anteriores del fichero ¿qué cosas podrían estar mal en dicha entrada? Varias cosas:
- Que v no estuviera definida.
- Que i no estuviera definida.
- Que i estuviera definida pero no fuera de tipo entero.
- Que v estuviera definida pero no fuera un array.
- Que v, aunque fuera un array, no fuera un array de enteros y, por tanto, v[i] no se pudiera sumar con el 2.
Todos estos tipos de errores, y otros más, todavía están sin detectar. Pero, tal y como se vio anteriormente, esta fase es la última de entre las de análisis y, por tanto, de aquí no puede pasar ningún programa con errores (que puedan ser detectados en tiempo de compilación, por supuesto).
Esta fase es una de las más amplias de un traductor. Por ello, para que sea más manejable, se suele subdividir, al menos, en dos etapas: la etapa de Identificación y la etapa de Comprobación de Tipos.
Etapa de Identificación
Esta etapa comprueba que todo símbolo que se use en el programa (variables, funciones, estructuras, clases, etc.) haya sido definido en algún lugar del programa. Si no es así, no tiene sentido seguir compilando.
Volviendo al ejemplo anterior:
print v[i] + 2;
De los cinco errores antes indicados, esta etapa sería la que detectaría los dos primeros: que las dos variables v e i hayan sido definidas en el programa.
Cómo se hace
Supóngase el siguiente programa de ejemplo:
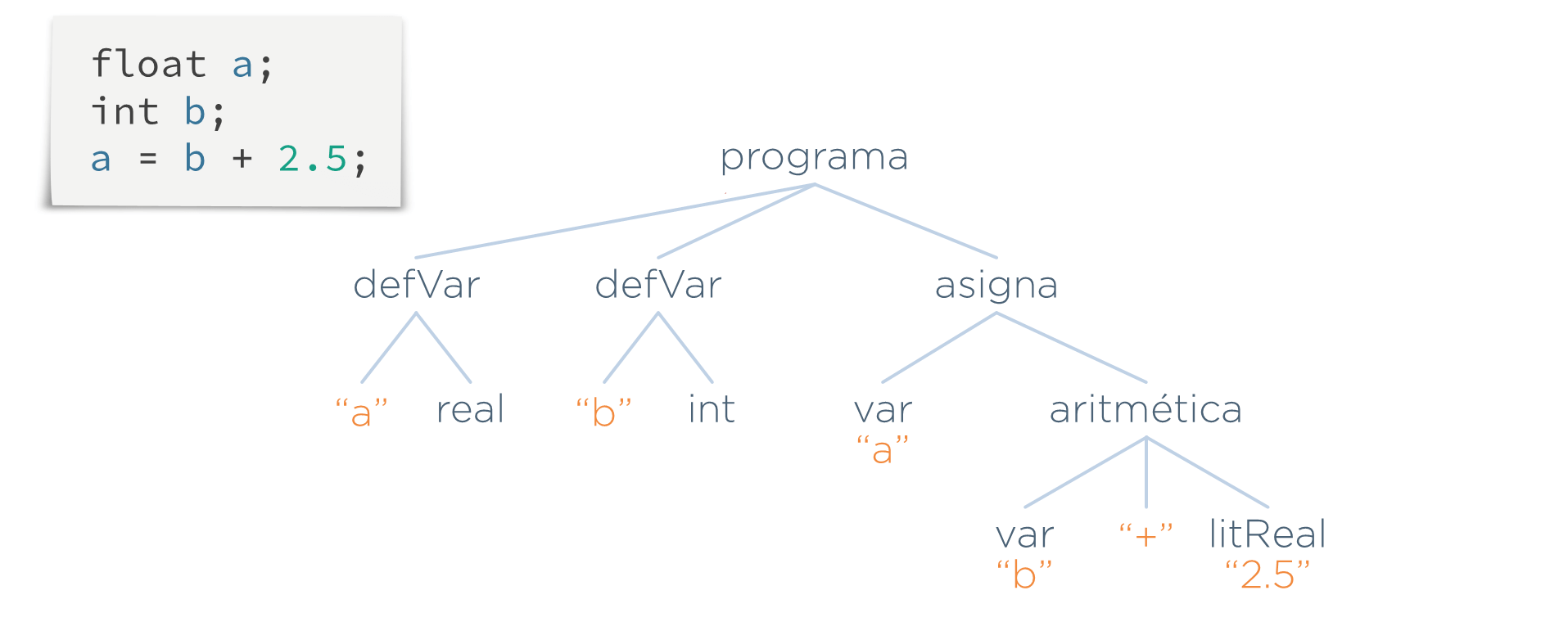
Lo que hace esta etapa es recorrer el AST y, cada vez que se encuentre una referencia a una variable (un nodo var), se busca si existe una definición con el mismo nombre de variable (un nodo defVar). En el caso del nodo var("a"), como existe un nodo defVar("a"), se marcaría dicho nodo como válido:
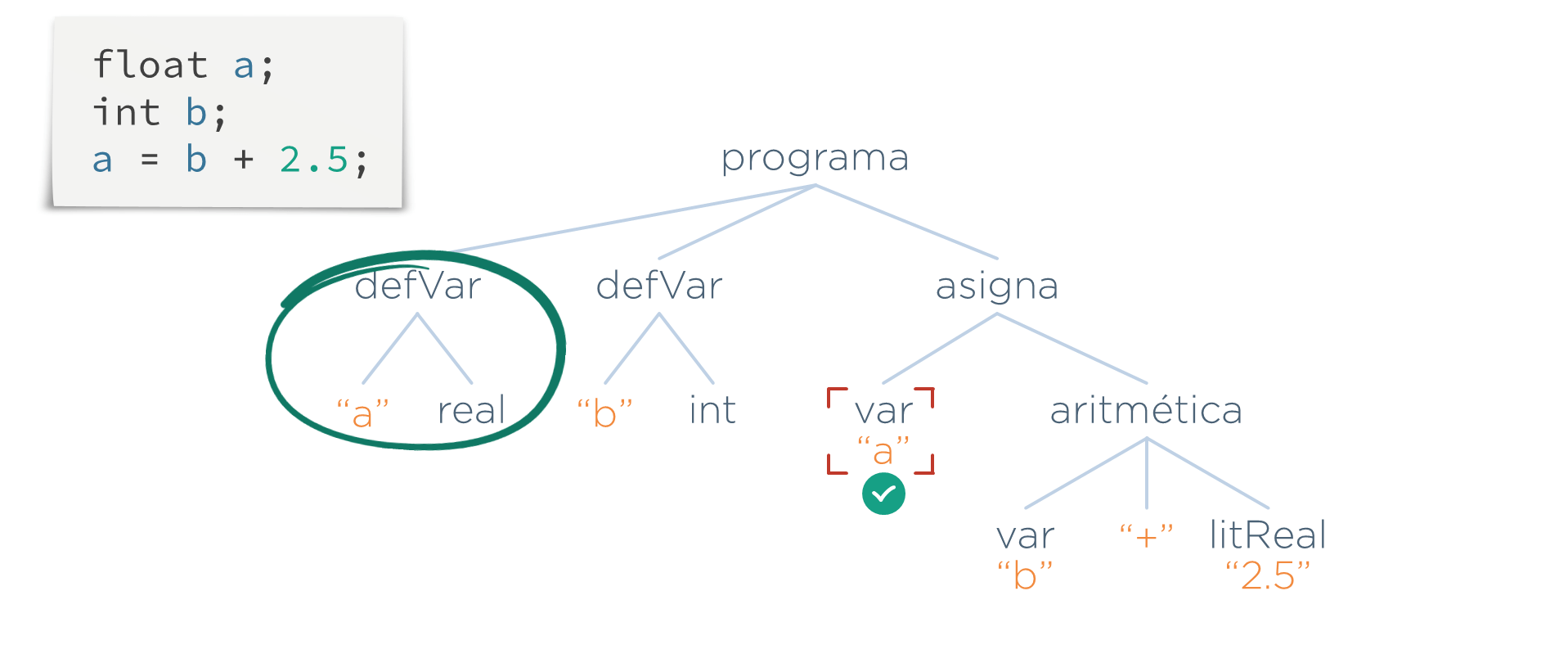
Lo mismo ocurre en el caso la variable b:
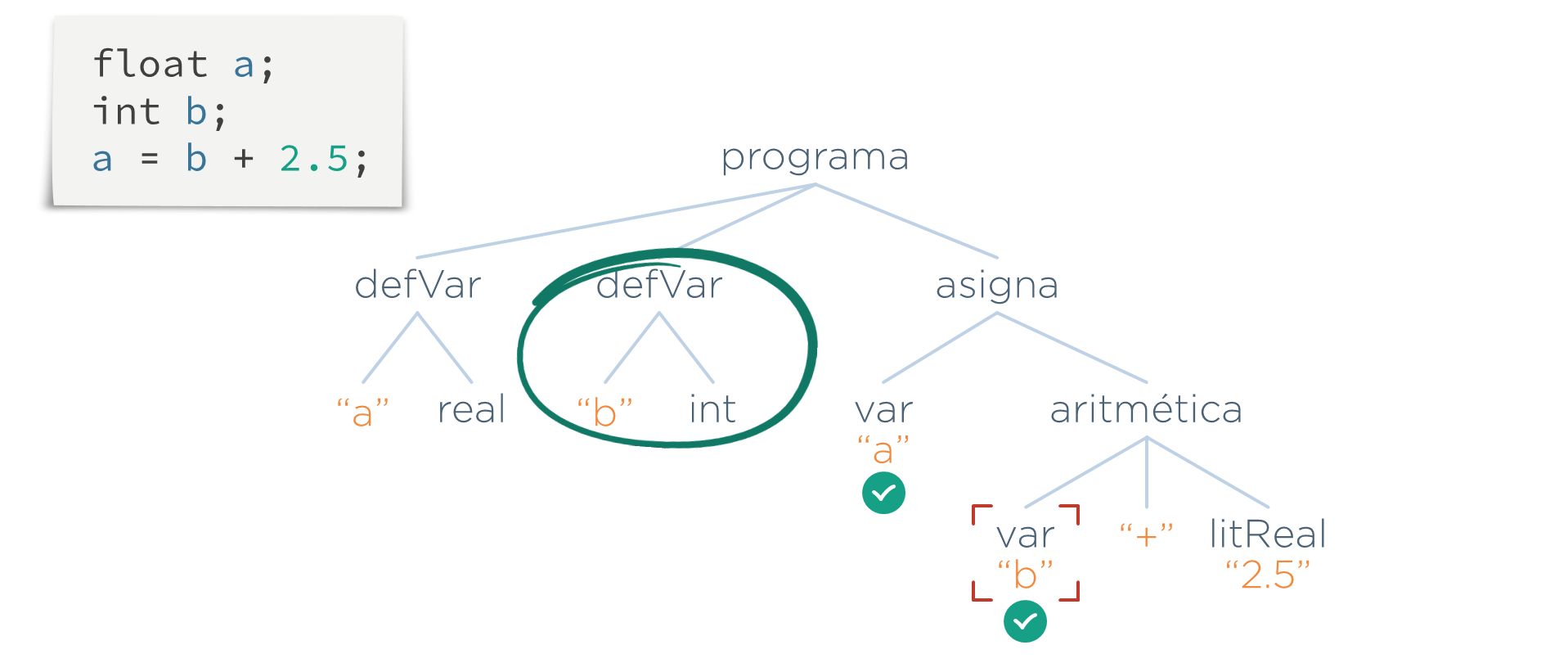
Una vez que se ha comprobado que todo símbolo usado ha sido definido, el programa quedaría validado por esta etapa.
Si hubiera un sólo símbolo que no hubiera estado definido, la entrada quedaría rechazada y no se seguiría con las siguientes fases.
Enlace de Definiciones
Esta etapa, además de comprobar que todo nodo var(n) tiene su defVar(n), hace algo más. Las fases posteriores del traductor necesitarán saber cómo se ha definido cada símbolo (su tipo, su ámbito, etc…). Para que no tengan que repetir la búsqueda de la definición del símbolo que ya se ha hecho aquí, esta etapa deja un enlace desde el símbolo (variable, función, tipo, etc...) hacia a su definición.
En el ejemplo anterior, se añadiría un enlace que va desde cada uso de una variable (nodo var) a su definición (nodo defVar). Por tanto, este sería el AST que saldría de esta etapa.
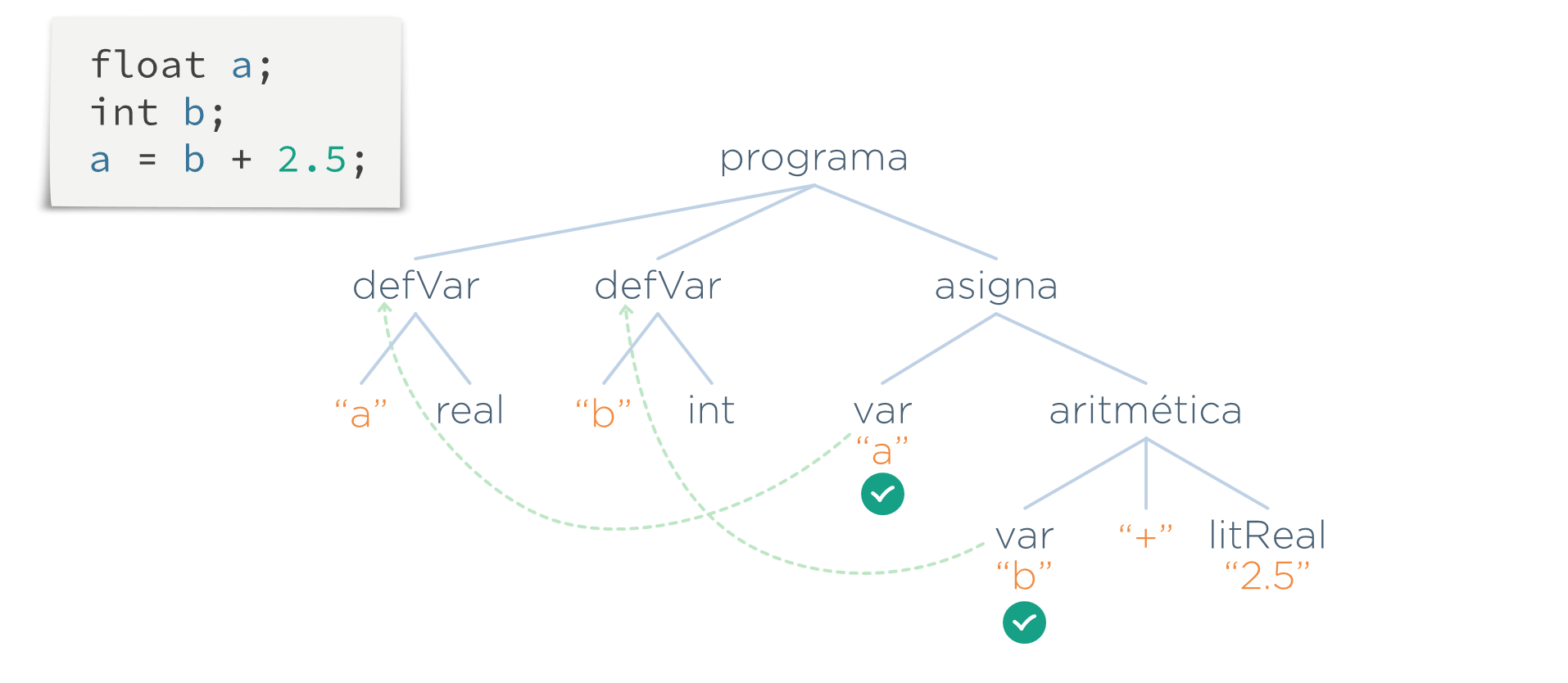
Nótese que, en realidad, la estructura de datos con la que se está trabajando ha pasado de ser un árbol a ser un grafo. Sin embargo, informalmente se le sigue llamando árbol igualmente.
Etapa de Comprobación de Tipos
Esta etapa se encarga de comprobar toda aquella situación relativa a los tipos. Algunos ejemplos de situaciones que serían detectadas por esta etapa son:
- Operar (sumar, multiplicar, dividir, ...) tipos incompatibles.
- Llamadas a funciones con un número o tipo erróneo en los argumentos.
- Asignaciones a variables de valores incorrectos.
Volviendo al ejemplo inicial:
print v[i] + 2;
De los cinco errores inicialmente indicados, esta etapa sería la que detectaría los tres últimos:
- Que i no sea de tipo entero.
- Que v no sea un array.
- Que v[i] no sea un tipo numérico (es decir, que v no sea un array de enteros).
Cómo se hace: Predicados, Atributos y Funciones Semánticas
Supóngase la siguiente programa entrada y su AST correspondiente: 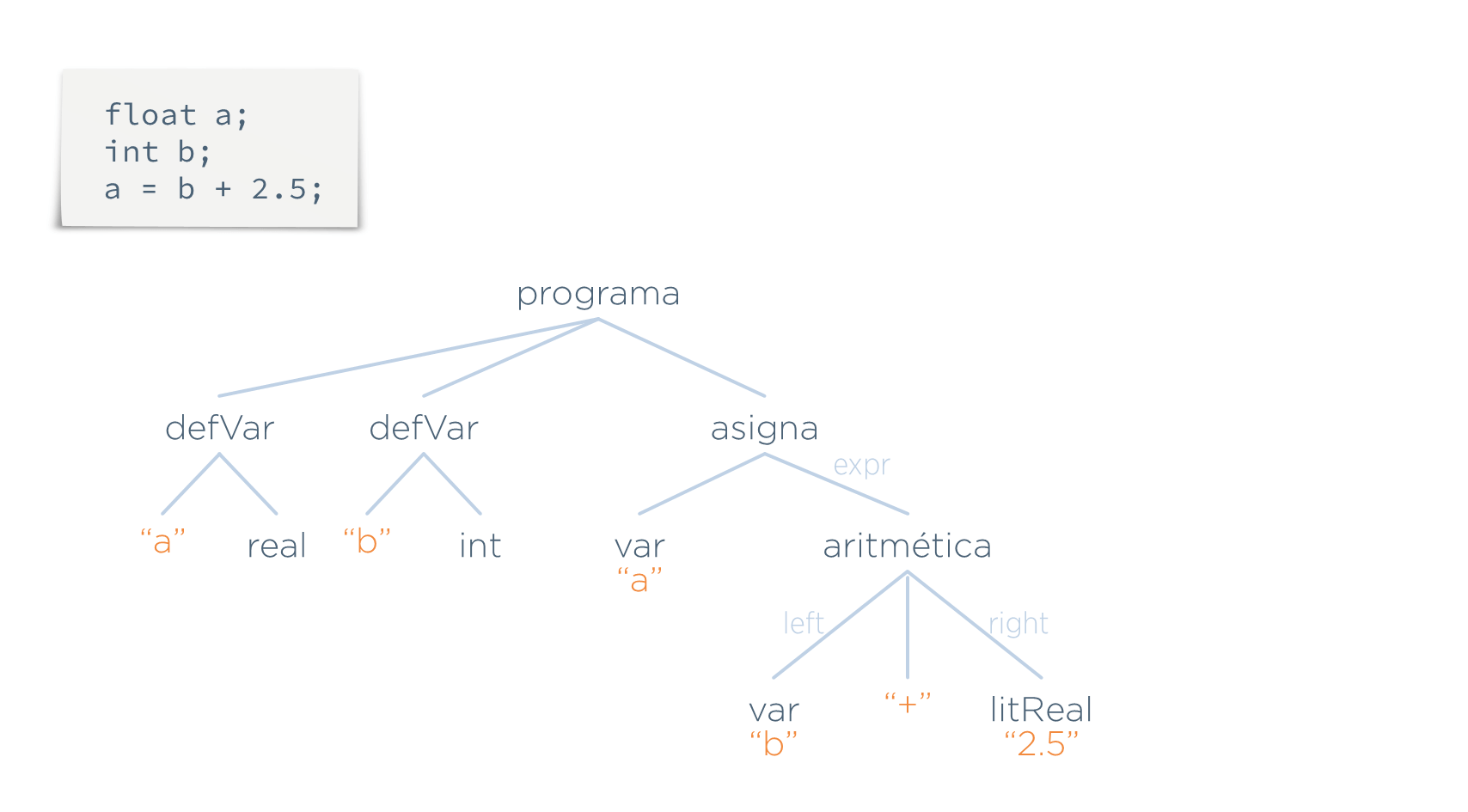
Para comprobar que las operaciones se están realizando con operandos del tipo adecuado, se asocian al AST predicados que detectan aquellas situaciones que no sean válidas. Son las condiciones que deben cumplir los nodos del árbol para que sean considerados válidos.
Supongamos que en este lenguaje ficticio hay dos normas:
- No se puede asignar un valor real a una variable entera.
- Los operandos de una suma deben ser numéricos (supongámos que en el lenguaje hay más tipos aparte de estos).
Estas normas se reflejan mediante predicados que se asocian a ciertos nodos del árbol (en la imagen, son las notas con fondo de color arena).
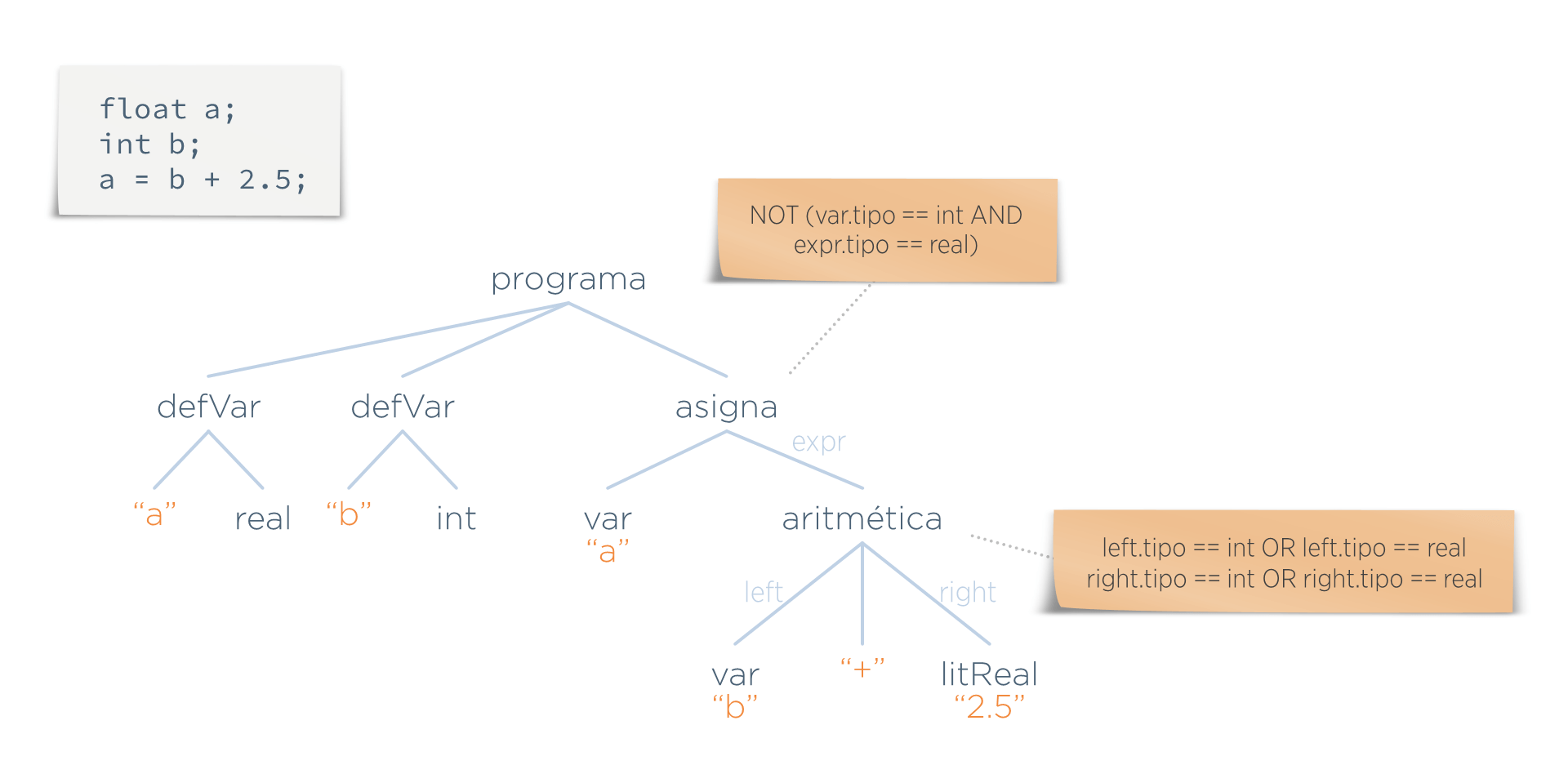
Pero lo normal es que estos predicados necesiten más información de la que hay en el AST. Por ejemplo, en el predicado superior ¿de dónde se saca el tipo del nodo asigna que se menciona en dicho predicado?
Por tanto, para realizar esta etapa, suele ser necesario añadir más información a ciertos nodos del AST. A esta información que se añade se la llama atributos. En este caso, los atributos serían los cuatro valores tipo añadidos a los nodos var, aritmética y litReal.
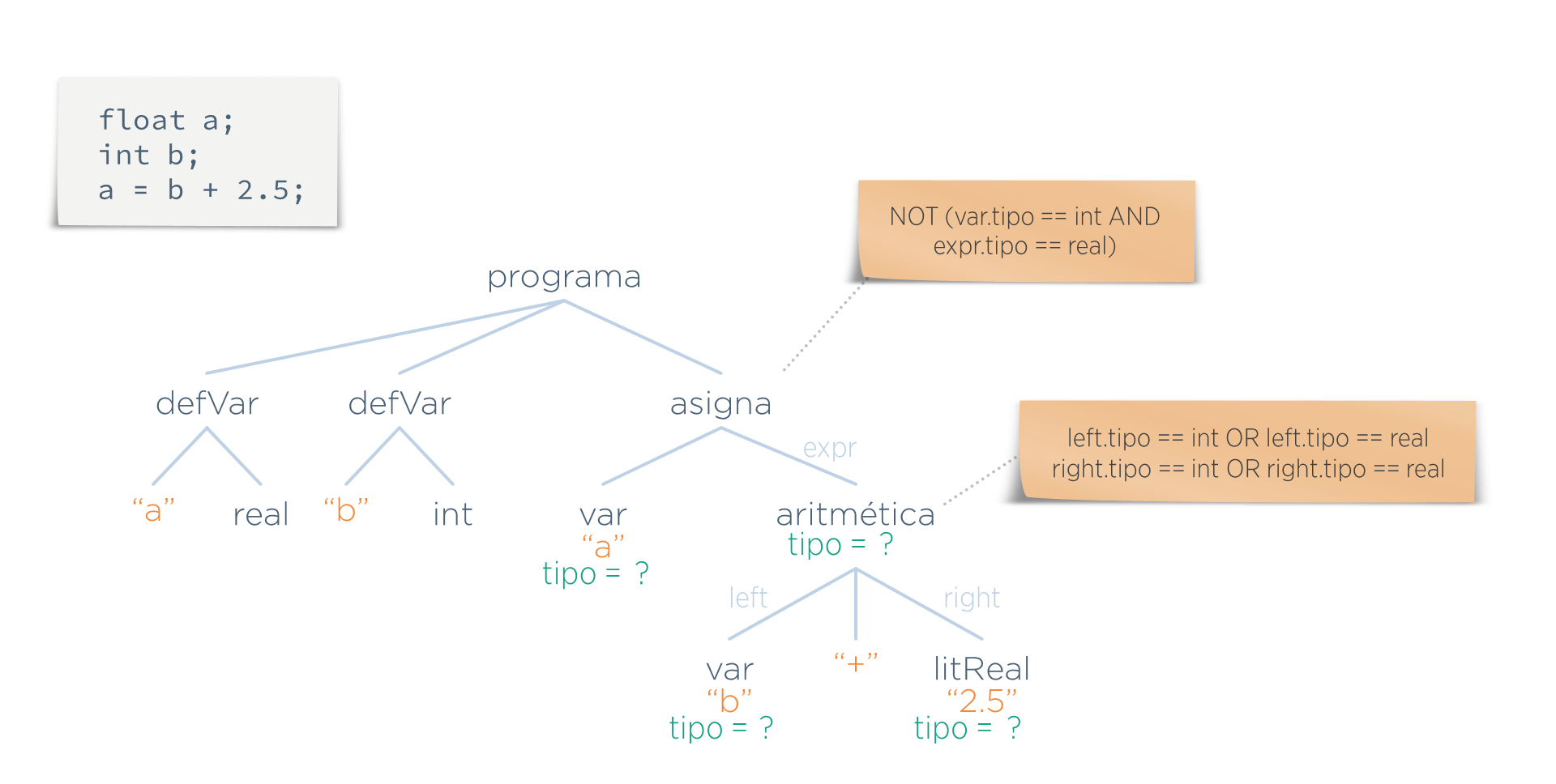
Pero ¿qué valor tiene ese atributo en cada nodo? Para eso están las funciones semánticas: indican qué valor tiene que tomar cada atributo en cada nodo. En la imagen siguiente se han representado como notas con fondo verde.
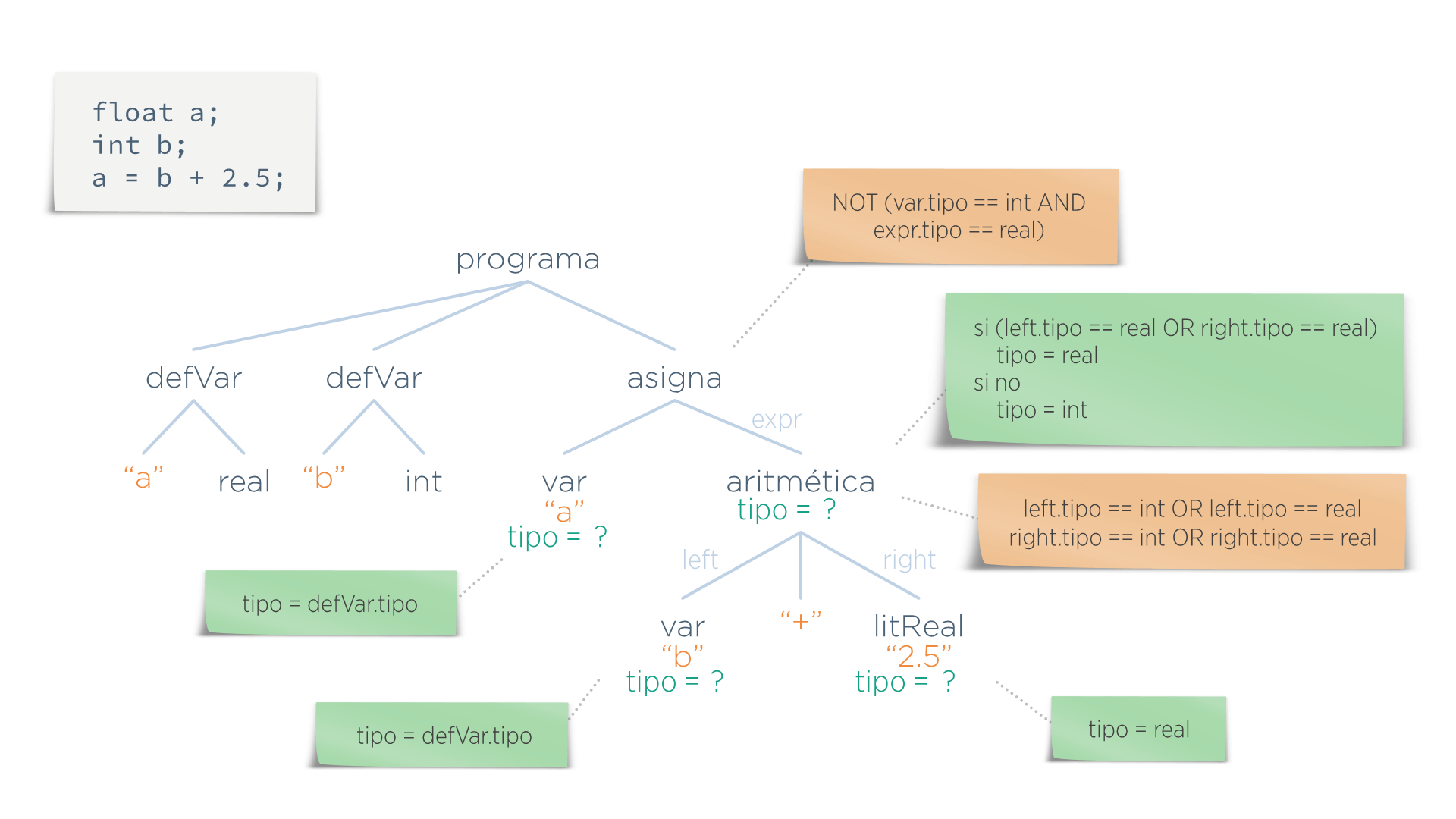
Una vez definidos estos tres elementos (predicados, atributos y funciones semánticas), ya se puede validar el árbol. Para ello hay que recorrer el AST realizando los siguientes pasos:
- Se asigna valor a los atributos ejecutando las funciones semánticas.
- Una vez que ya tienen valor, se evalúan los predicados y se obtiene su valor (true o false). Si todos los predicados acaban con valor true, la entrada es válido. Por el contrario, con sólo uno de los predicados con valor false, además de emitir su mensaje de error asociado, la entrada se rechaza y no se pasa a la siguiente fase.
En el ejemplo anterior, el resultado del primer paso es el que se muestra en la siguiente imagen, donde se ve que todos los atributos tipo han tomado el valor que indica su función semántica asociada. Nótese que los nodos var toman su tipo del nodo defVar con el que se enlazaron en la etapa de identificación (los enlaces se han omitido para no recargar la imagen). 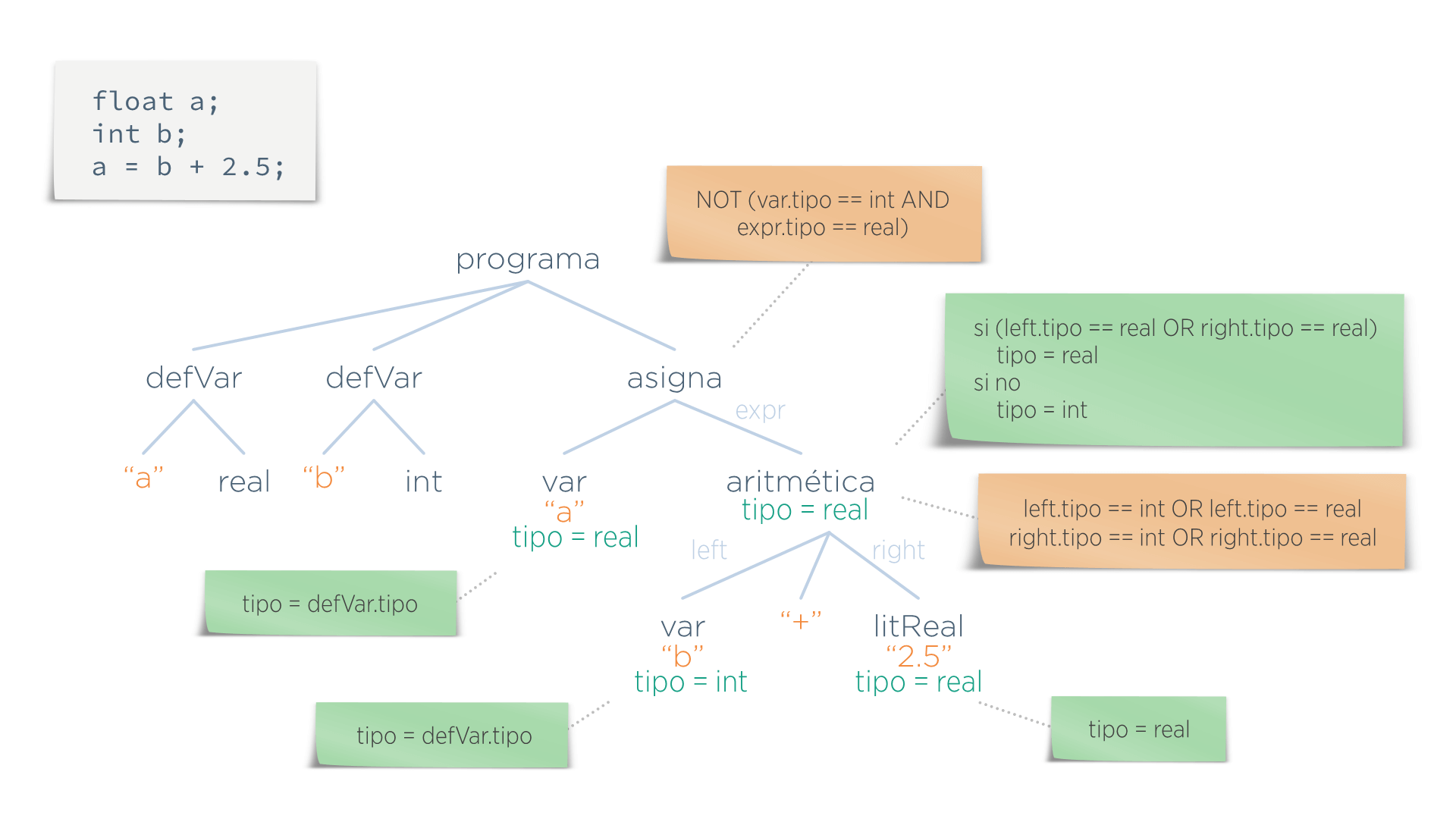
Una vez que se dispone de dichos valores, ya se puede realizar el segundo paso comprobando los predicados. 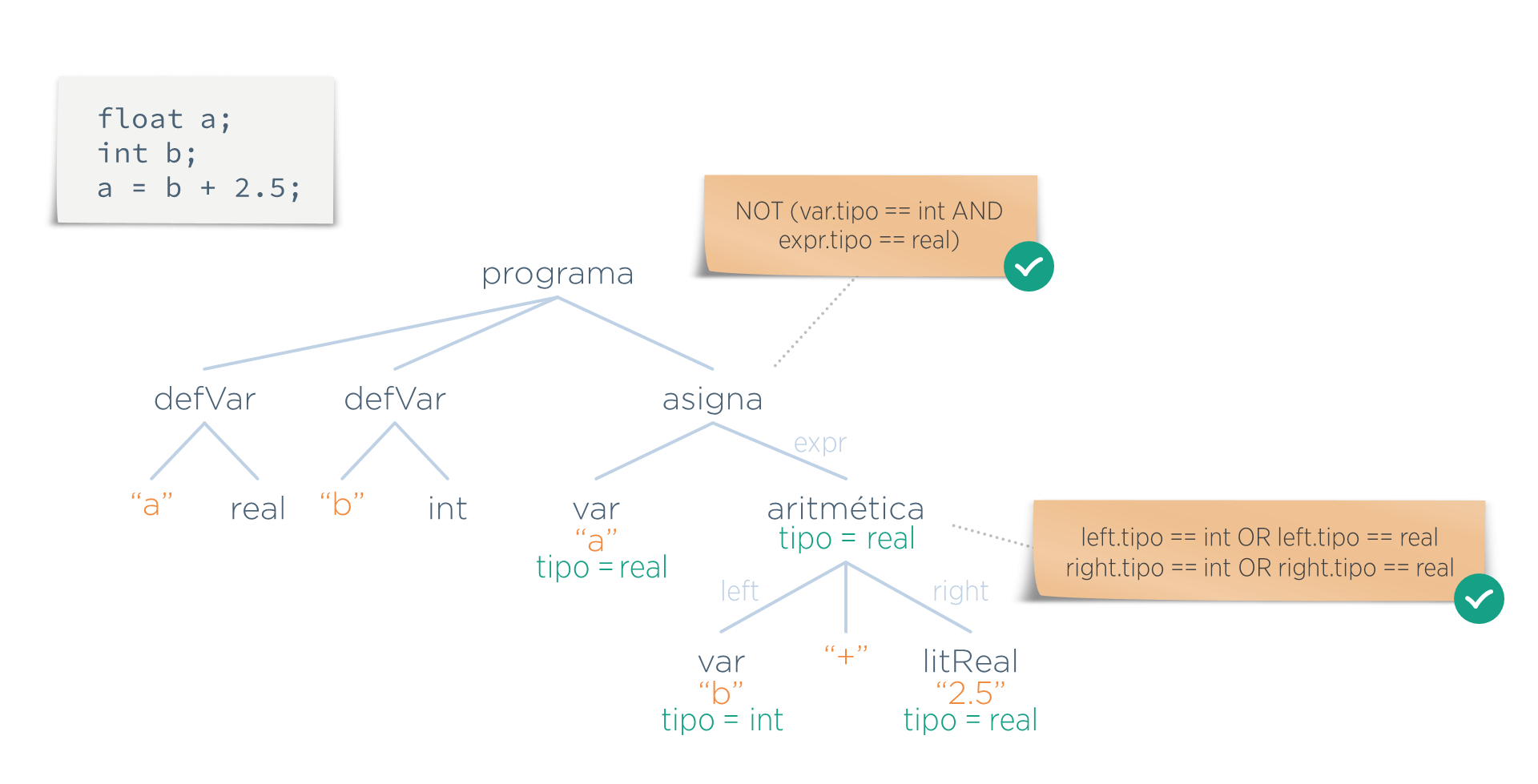
En el ejemplo anterior, ambos predicados serían true (las marcas ✔ sobre los predicados), por lo que la entrada sería semánticamente válida.
Por último aclarar que, aunque para explicar el proceso han hecho dos recorridos del árbol (uno para ejecutar las funciones semánticas y otra para evaluar los predicados), posteriormente se verá que normalmente se pueden hacer ambas tareas con un solo recorrido del árbol.