Símbolos Directores Comunes
Símbolos Directores
Los símbolos directores (SD) de una regla son aquellos tokens que, a la hora de tener que elegir entre varias reglas, si aparecen a la entrada indican que hay que seleccionar dicha regla. En realidad, son todos aquellos tokens que pueden aparecer como primer token en alguna de las cadenas que se puedan generar a partir de dicha regla.
Por ejemplo:
a ⟶ IDENT IDENT
| b NUM
b ⟶ X | Y
Los símbolos directores de las dos reglas de a son:
- SD(IDENT IDENT) es sólo el token IDENT.
- SD(b NUM) son los tokens { X, Y }. Es decir, las dos cadenas que se pueden generar a partir de la cadena 'b NUM' son 'X NUM' e 'Y NUM'. De estas cadenas, se coge el primer token de cada una.
Estos símbolos directores son los que, como se vio en la implementación de Reglas con Antecedente Común, hay que utilizar en los if para saber por qué regla ir.
En el ejemplo anterior, la implementación de las reglas del antecedente a, usando los símbolos directores de cada regla, sería:
void a() {
if (getToken() == Lexicon.IDENT) {
match(Lexicon.IDENT);
match(Lexicon.IDENT);
} else if (getToken() == Lexicon.X || getToken() == Lexicon.Y) {
b();
match(Lexicon.NUM);
} else
error();
}
Colisión de Símbolos Directores
A la hora de elegir entre varias reglas con el mismo antecedente, no debería haber ningún token que estuviera entre los símbolos directores de más de una de ellas. Si esto ocurriera, al aparecer dicho token en la entrada, no se sabría cual de las reglas aplicar.
Ejemplo 1
Por ejemplo, supóngase la siguiente gramática.
a ⟶ IDENT IDENT
| b NUM
b ⟶ IDENT
La implementación recursiva descendente seria:
void a() {
if (getToken() == Lexicon.IDENT) {
match(Lexicon.IDENT);
match(Lexicon.IDENT);
} else if (getToken() == Lexicon.IDENT) {
g();
match(Lexicon.NUM);
} else
error();
}
Aquí se ve el problema de que un token esté entre los símbolos directores de más de una regla (con mismo antecedente). En este caso, puede verse que el token IDENT está entre los símbolos directores tanto de 'a ⟶ IDENT IDENT' como de 'a ⟶ b NUM'. Por tanto, en la implementación anterior nunca se metería por la segunda rama del if.
Esto haría que una entrada válida tal como 'a 24' fuera erróneamente clasificada como inválida.
El algoritmo que comprueba si una gramática es LL(1) rechazaría una gramática que presentara dicha situación. De hecho, simplificando, lo que básicamente hace dicho algoritmo es calcular los símbolos directores de todas las reglas con el mismo antecedente y comprobar que no hay ningún token repetido en ellos.
Ejemplo 2
En el ejemplo anterior el calcular los símbolos directores era trivial. Sin embargo, no es una tarea que se deba hacer a ojo, ya que enseguida puede complicarse la tarea, por ejemplo, en cuanto aparezcan producciones a vacío (ε). En la siguiente gramática, aunque a simple vista no se vea, hay dos reglas con el mismo antecedente que comparten símbolos directores:
s ⟶ c d g
c ⟶ NUM | IDENT
d ⟶ NUM | f g
f ⟶ PRINT NUM | ε
g ⟶ IDENT | NUM
El problema está en las dos reglas que tienen a d como antecedente.
En la primera regla 'd ⟶ NUM' es fácil ver que su único símbolo director es el token NUM.
En la regla 'd ⟶ f g', sus símbolos directores son los tokens { PRINT, IDENT y NUM }.
El primer token se obtiene si f se sustituye aplicando la primera de sus reglas. Pero f también puede sustituirse por su segunda regla y anularse. En este caso, serían los símbolos directores de g (IDENT y NUM) los que formarían parte de los símbolos directores de d.
Por tanto, el token NUM forma parte de los símbolos directores de ambas reglas de d.
Este ejemplo pretende mostrar que no es conveniente calcular los símbolos directores a ojo, ya que a veces se pueden pasar por alto ciertas situaciones, y por ello que se debe comprobar la gramática antes de implementarla usando una herramienta.
Situación
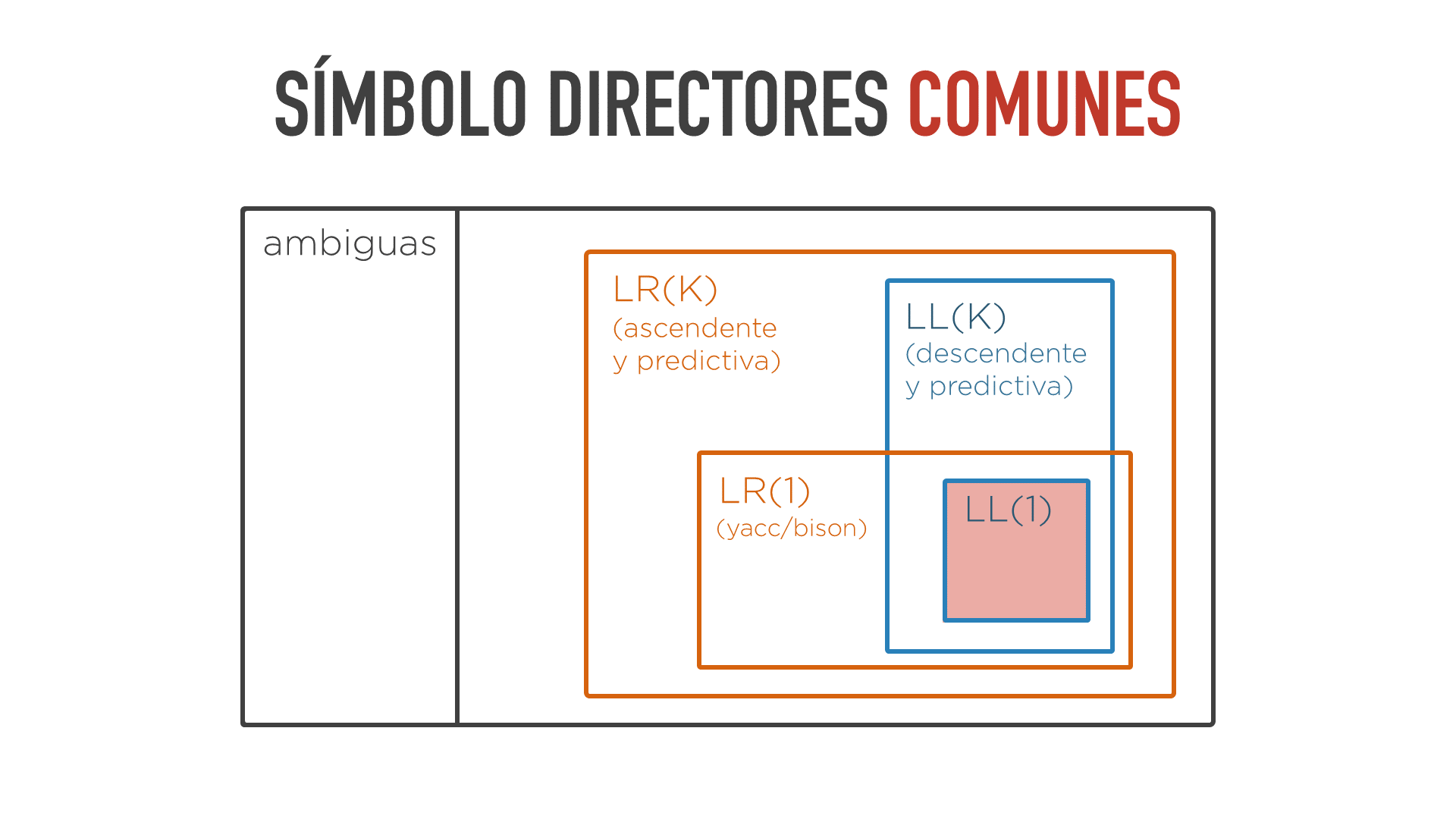
Una gramática que tenga símbolos directores comunes en reglas con el mismo antecedente no podría implementarse usando un parser LL(1), es decir, no puede ser implementada con un parser descendente predictivo que mire un sólo token hacia adelante.
Por tanto, la gramática no puede ser LL(1) y, dentro del mapa de gramáticas, no podría estar en la zona señalada en rojo.
Posibles Soluciones
Las opciones más comunes a la hora de implementar una gramática que no sea LL(1) son:
- Leer más tokens de la entrada.
- Cambiar de dirección de reconocimiento del parser.
- Buscar una gramática equivalente.
Leer más Tokens
Siguiendo con una técnica descendente, se podría cambiar la implementación del parser para ampliar el número de tokens a mirar, es decir, pasar de un parser LL(1) a un parser LL(k) con k > 1.
Esta opción cabría plantearsela si se va a implementar mediante una herramienta, ya que cuando k es mayor que 1 se complica la implementación manual.
Cambiar la Dirección
Otra opción es cambiar de dirección de reconocimiento del parser y pasar a uno ascendente. Como ya se vio en el tema anterior, esta técnica es más potente y puede que la gramática sí cumpla los requisitos más permisivos de la técnica LR(1). Así, se podría volver a una técnica más eficiente ya que sólo necesita leer un token de nuevo.
La herramienta clásica para implementar este tipos de parsers es yacc (aunque esta herramienta no se verá por falta de tiempo). Esta fue la solución predominante hasta que ANTLR se postuló como otra opción a considerar.
Gramática Equivalente
Las dos soluciones anteriores, debido a su complejidad, requieren del uso de una herramienta. Sin embargo, si se prefiere el control y la sencillez que ofrece una implementación manual (o bien no se dispone de herramientas), la solución sería buscar una gramática equivalente que sí fuera implementable con la técnica recursiva descendente. Es decir, de las infinitas gramáticas equivalentes que generan un lenguaje, se trata de hallar otra gramática (partiendo de cero o transformando la gramática existente) que genere el mismo lenguaje y sí sea LL(1).
Como ejemplo de cómo se puede llevar a cabo esta opción, se presenta un ejemplo de una solución habitual para un problema puntual (no es una técnica general para resolver obtener gramáticas LL(1)). Supóngase la siguiente gramática:
a ⟶ IDENT IDENT
| b NUM
b ⟶ IDENT
Como se vio anteriormente, las dos reglas que tienen a a de antecedente tienen a IDENT como símbolo director común. En estos casos, lo que se puede es sacar factor común a estas reglas mediante la siguiente transformación:

La nueva gramática obtenida sí es LL(1) y, por tanto, puede implementarse de manera recursiva descendente.
Qué hace ANTLR
ANTLR, ante una gramática que presente reglas con el mismo antecedente y símbolos directores comunes, opta por la primera de las tres soluciones anteriores, es decir, en vez de quedarse en k = 1, sigue mirando tantos tokens como sea necesario para saber por qué regla seguir.

Es por esto que el autor de la herramienta denomina a las gramáticas que pueden ser tratadas por esta herramienta como LL(*), queriendo indicar con el asterisco que, en vez de un k fijo, este valor cambia en tiempo de ejecución hasta el valor que sea necesario.