Implementación con ANTLR
Características de ANTLR
Una vez vistos los conceptos básicos de cómo implementar un parser de manera manual, en este capítulo se verá como hacerlo con una herramienta. De esta manera, en vez de tener que hacer el código, se le da a la herramienta la especificación sintáctica (con una notación que suele ser una variante de los metalenguajes sintácticos vistos) y es ella la que se encarga de generarlo.
La herramienta a utilizar, de nuevo, es ANTLR en su versión 4. Esta herramienta, como ya se ha visto, vale tanto para hacer analizadores léxicos como sintácticos.
Las características de ANTLR, en lo que a analizadores sintácticos se refiere, son:
- Admite reglas tanto en BNF como en EBNF (en realidad, se podría simplificar esto diciendo simplemente que admite EBNF, ya que BNF es un subconjunto).
- Genera un parser utilizando básicamente la técnica recursiva descendente. Esto quiere decir que:
- Es descendente.
- Es predictivo (no hace backtracking).
- Cada regla se implementa como un método. La implementación de ese método se corresponde con los símbolos de su consecuente.
La diferencia fundamental de esta herramienta frente a la técnica recursiva descendente vista anteriormente es que, esta última, sólo miraba un token hacia adelante (es decir, sólo valía para gramáticas LL(1) — aquellas que pudieran ser tratadas mirando un sólo token de la entrada en cualquier situación). Sin embargo, ANTLR puede mirar tantos tokens como sea necesario. Por ello, el autor lo denomina un parser LL(*) y, a las gramáticas que puede implementar, les da el mismo nombre.
Estas gramáticas no están tan estudiadas como las LL(k) y las LR(k) y no está tan claro su relación, especialmente con las últimas. Por tanto, son difíciles de situar en el mapa de las gramáticas. De manera intuitiva, podrían ocupar la zona azul.
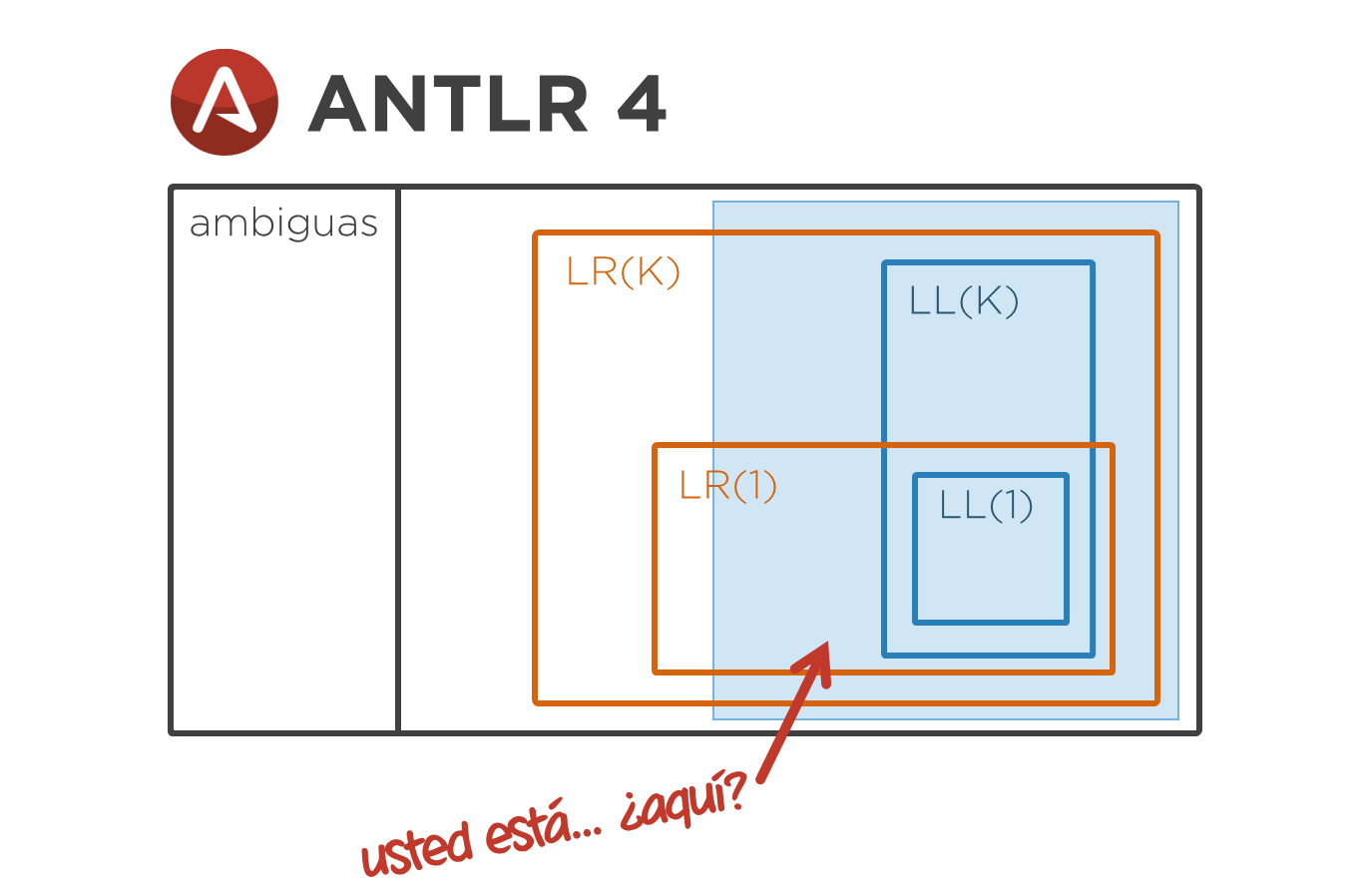
Se puede ver que:
- Incluyen a las gramáticas LL(k).
- No incluyen a las gramáticas LR(k). La razón de esto es que, como luego se verá, las gramáticas LL(*) no admiten ciertos tipos de recursividad a izquierda, cosa que sí hacen las LR(k).
Generación de un Parser con ANTLR
Supóngase que se quiere hacer un parser de la siguiente gramática.
start ⟶ NUM a IDENT
a ⟶ NUM
Dicha especificación se pasa al formato de ANTLR en el fichero Grammar.g4 (el nombre y la extensión no tienen por qué ser estos).
grammar Grammar;
import Lexicon;
start : NUM a IDENT EOF;
a : 'print' NUM;
En este fichero hay cosas nuevas a destacar:
- Se usa
grammar Grammarsin ponerlexeren medio. Esto sólo se ponía para generar analizadores léxicos. Como en este caso es un sintáctico, no hay que ponerlo. - Aunque el léxico y el sintáctico pueden hacerse en el mismo fichero, aquí se ha optado por hacerlos en ficheros separados ya que esto permite tratar cada fase de manera independiente. En este caso, hay que usar import para indicar el nombre de la clase que implementa el analizador léxico.
- Los no-terminales (start y a en este caso) tienen que empezar por minúscula (para que ANTLR no los confunda con tokens) y no pueden ser palabras reservadas de Java (if, while, return, ...).
- Se pueden poner los mismos comentarios que en Java (el de una y el de varias líneas).
- En la regla
a : 'print' NUM, puede observarse que se ha escrito directamente el lexemaprinten vez de poner un token. Aunque se podría hacer como en el tema anterior, es más cómodo usar este atajo que consiste en que si se pone en el sintáctico un lexema entre comillas simples, ANTLR automáticamente crea dicho token en el léxico por nosotros. La regla anterior sería equivalente a lo siguiente:// En el sintáctico a : PRINT NUM;// En el léxico PRINT: 'print'; // Esto lo hace ANTLR automáticamente
Siguiendo con el ejemplo, el analizador léxico, que también se hará con ANTLR, se especifica en el fichero GrammarLexer.g4. Nótese que el nombre Lexicon dado en lexer grammar Lexicon coincide con el nombre dado en el import en el sintáctico.
lexer grammar Lexicon;
NUM : [0-9]+;
IDENT : [a-zA-Z_]+;
// PRINT: 'print'; // Ya no es necesario poner tokens de un sólo lexema
WS : [ \t\r\n]+ -> skip;
Finalmente, se utiliza ANTLR para obtener el código de ambos analizadores (léxico y sintáctico):
java -jar "antlr\antlr-4.7.2-complete.jar" -no-listener -package parser "Grammar.g4"
Después del comando anterior, habrán aparecido dos ficheros Java nuevos, cada uno de los cuales implementa uno de los analizadores.
c:/pruebas>dir
GrammarLexer.java
GrammarParser.java
...
Si se observa el código generado (sólo por curiosidad, ya que no es necesario conocerlo), se pueden ver vestigios de la técnica recursiva descendente. Puede verse como, de la regla start : NUM a IDENT EOF, ANTLR ha sacado un método con el nombre del antecedente (start()). Y en su implementación, entre otro código, pueden verse los match de los tokens de la regla y la llamada al método a(), tal y como se hacía a mano.
public final StartContext start() {
...
match(NUM);
setState(5);
a();
setState(6);
match(IDENT);
setState(7);
match(EOF);
...
}
Finalmente, se hace un main que pruebe el analizador sintáctico.
GrammarLexer lexer = new GrammarLexer(CharStreams.fromFileName("source.txt"));
GrammarParser parser = new GrammarParser(new CommonTokenStream(lexer));
parser.start();
if (parser.getNumberOfSyntaxErrors() > 0)
System.out.println("\n>>> Análisis finalizado con errores");
else
System.out.println("\n>>> Analizador Finalizado con éxito");
Y con esto se habría acabado la implementación del parser de este ejemplo.
Código
💿 Se puede bajar el proyecto Java con todo lo necesario para poder ejecutar la solución de este ejemplo y así poder ver su resultado y probar otras alternativas.
Asociatividad en ANTLR
ANLTR asume asociatividad a izquierda en los operadores, ya que es la más habitual.
expr : expr '^' expr
| NUM;
Con la gramática anterior, la entrada 1 ^ 2 ^ 3 se interpretaría como (1 ^ 2) ^ 3. Sin embargo, el operador potencia tiene asociatividad a derecha, por lo que la interpretación anterior sería erronea.
Para indicar que el operador debe reconocerse con asociatividad a derecha, se usa el modificador <assoc=right> al inicio de la regla.
expr : <assoc=right> expr '^' expr
| NUM;
De esta manera, la entrada se interpretaría correctamente como 1 ^ (2 ^ 3).