Parser Recursivo Descendente
Existen varias técnicas para implementar un parser de forma manual. Aquí se verá la técnica Recursiva Descendente, que sirve para implementar parsers LL(1).
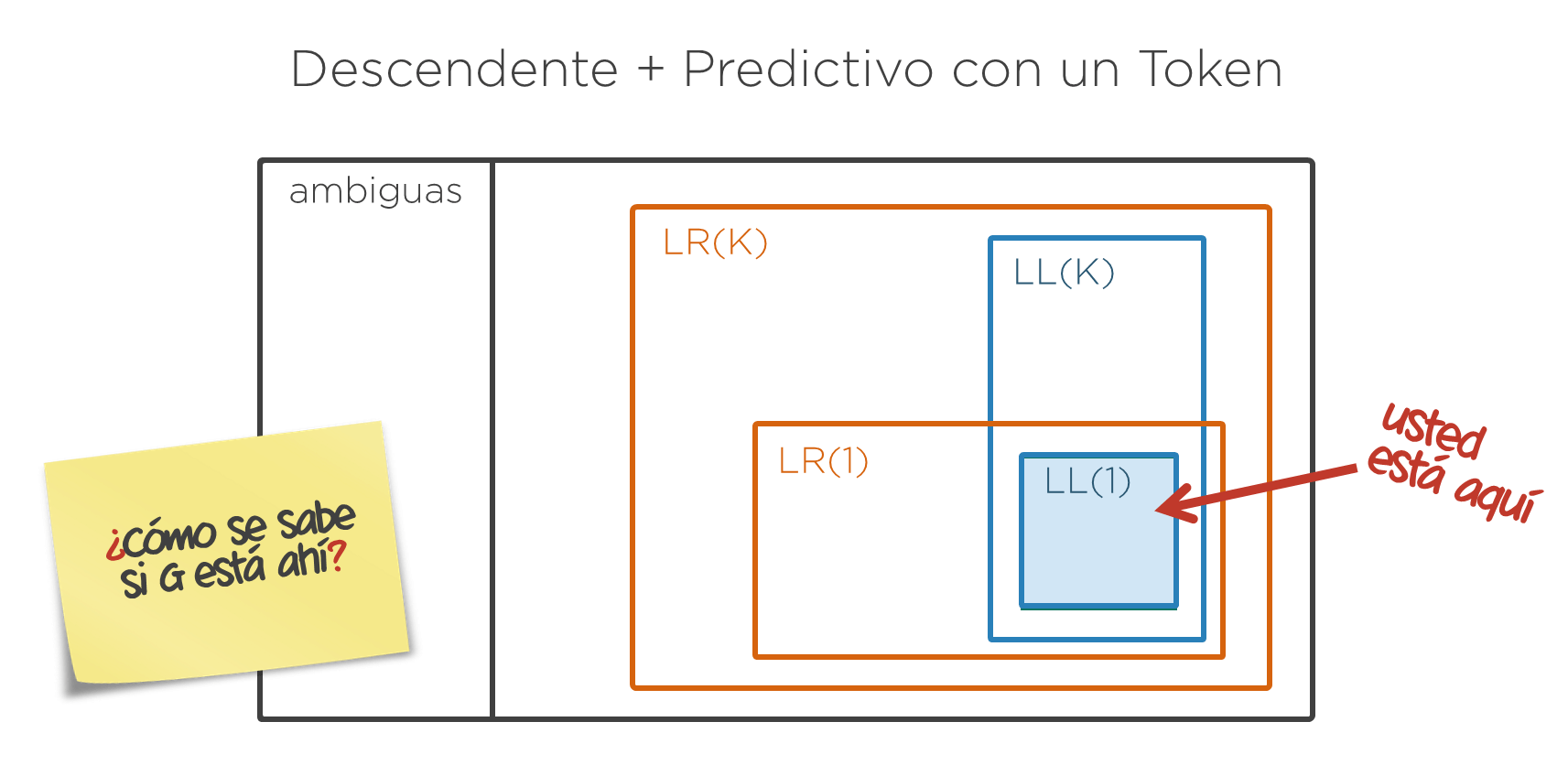
Por ello, hay que asegurarse que la gramática a implementar cumple los requisitos para ser implementada de esta manera, es decir, que sea una gramática LL(1). Básicamente, el requisito es que mirando un sólo token nunca, en ninguna situación posible, haya ambiguedad sobre qué regla hay que elegir. Esto, si la gramática es sencilla, puede hacerse a mano. Sin embargo, lo más adecuado es utilizar una herramienta que lo compruebe. En esta asignatura no se verá dicha comprobación por falta de tiempo y los ejemplos aquí usados se suponen ya verificados como LL(1).
Este método fue creado originalmente para implementar el lenguaje de programación Pascal y ha sido uno de los más usados a la hora de realizar implementaciones manuales (por ejemplo, también fue usado en la implementación del lenguaje BASIC).
Implementación
Antes de empezar la implementación, se necesita la siguiente infraestructura que es común a cualquier parser independientemente de la gramática a implementar.
public class RecursiveParser {
private Lexicon lex;
public RecursiveParser(Lexicon lexico) throws ParseException {
lex = lexico;
advance();
}
// ------------------------------------------------------------------------
// ------ Miembros auxiliares para todo parser recursivo descendente
private Token token;
private void advance() {
token = lex.nextToken();
}
private void error() throws ParseException {
throw new ParseException("Error sintáctico en " + token.getLine() + ":"
+ token.getCharPositionInLine() + ". Lexema = " + token.getText());
}
void match(int tokenType) throws ParseException {
if (token.getType() == tokenType)
advance();
else
error();
}
// # ------------------------------------------------------------------------
// # Aquí comienza el Analizador Sintáctico
// #
public void start() throws ParseException {
...
}
}
La infraestructura consiste en:
- Un método advance que lea el siguiente token.
- Un método error donde se centraliza el procesamiento de los errores sintácticos.
- Un método match que compruebe si el token actual es el indicado en el parámetro. Si es así, pasa al siguiente token. En caso contrario, notifica de que la entrada no es válida.
Debajo de estos métodos, empezarían ya los métodos propios de la gramática.
Implementación de una Regla
La técnica recursiva descendente se basa en implementar un método por cada regla de la gramática, siendo el consecuente de la misma el que indique su implementación.
Por ejemplo, supóngase la siguiente gramática:
start ⟶ IDENT a NUM
a ⟶ NUM IDENT
Con la anterior gramática, sería válida una entrada como:
hola 24 mundo 48
Lo primero que hay que hacer es especificar e implementar el léxico necesario para dicha gramática:
lexer grammar Lexicon;
NUM : [0-9]+;
IDENT : [a-zA-Z][a-zA-Z0-9_]*;
WS : [ \t\r\n]+ -> skip;
Ahora ya se podría hacer la implementación de la gramática:
public class RecursiveParser {
...
// start ⟶ IDENT a NUM
public void start() throws ParseException {
match(Lexicon.IDENT);
a();
match(Lexicon.NUM);
match(Lexicon.EOF);
}
// a ⟶ NUM IDENT
public void a() throws ParseException {
match(Lexicon.NUM);
match(Lexicon.IDENT);
}
}
A destacar:
- Dado que hay dos reglas en la gramática, hay dos métodos en la clase RecursiveParser con el mismo nombre.
- La implementación de un método consiste en implementar cada uno de los símbolos del consecuente de la regla en el mismo orden.
- Si el símbolo es un terminal, hay que invocar al método match con dicho token. Es decir, hay que comprobar que es el token actual de la entrada y pasar al siguiente.
- Si el símbolo es un no-terminal, hay que invocar al método que implementa la regla de dicho no-terminal. Es decir, simplemente hay que poner el símbolo seguido de paréntesis.
- En la implementación de la regla del símbolo inicial (
start()), hay que hacer un últimomatch(Lexicon.EOF)para comprobar que, al acabar el análisis, no haya más tokens a la entrada (lo cual indicaría que hay una entrada inválida, ya que se debería haber acabado la entrada).
Código
💿 Se puede bajar el proyecto Java con el código de este ejemplo.
Reglas con Antecedente Común
Supóngase la siguiente gramática:
start ⟶ IDENT a
a ⟶ NUM b IDENT
| IDENT b IDENT
b ⟶ IDENT
A la hora de implementarla, habría que crear un método por cada regla con el nombre del antecedente de la misma. Sin embargo, en la gramática anterior se tiene dos reglas con el mismo antecedente (a).
En este caso, el mismo método implementará ambas reglas añadiendo código que decida por cual de ellas ir en función de los símbolos directores de cada una. Los símbolos directores de una regla (definido de manera muy informal, ya que no se dispone del tiempo para definirlos formalmente), son los tokens que, de estar a la entrada, indicarían que dicha regla es la que hay que seleccionar para realizar la siguiente transformación (por la que hay que ir para encontrar el camino).
En las dos reglas anteriores, los símbolos directores de cada una serían:
- En
a ⟶ NUM b IDENT, serían {NUM}. - En
a ⟶ IDENT b IDENT, serían {IDENT}
Por tanto, la implementación final sería:
public class RecursiveParser {
...
// start ⟶ IDENT a
public void start() throws ParseException {
match(Lexicon.IDENT);
a();
match(Lexicon.EOF);
}
public void a() throws ParseException {
if (token.getType() == Lexicon.NUM) {
// a ⟶ NUM b IDENT
match(Lexicon.NUM);
b();
match(Lexicon.IDENT);
} else if (token.getType() == Lexicon.IDENT) {
// a ⟶ IDENT b IDENT
match(Lexicon.IDENT);
b();
match(Lexicon.IDENT);
} else // No olvidar esta rama
error();
}
// b ⟶ IDENT
public void b() throws ParseException {
match(Lexicon.IDENT);
}
}
El cálculo de los símbolos directores en este caso ha sido trivial, ya que las reglas eran muy sencillas. Sin embargo, en general, es necesario seguir un procedimiento que las calcule (a mano o con herramienta) ya que, a poco que la gramática se complique con derivaciones a vacío, no serán tan evidentes de ver a ojo.
Posteriormente se tratará algo más de este tema cuando se hable de símbolos directores comunes.
Código
💿 Se puede bajar el proyecto Java con el código de este ejemplo.
Ejemplo
✏️ En este punto se recomienda ver también el ejemplo 320.