Análisis Sintáctico
Descripción
El análisis sintáctico comienza su trabajo recibiendo los tokens encontrados en la fase anterior. Su misión es similar a la del analizado léxico pero a un nivel superior. Si el analizador léxico formaba tokens a partir de caracteres, el analizador sintáctico forma estructuras a partir de tokens.
Esta fase tiene unas reglas (cuyo formato ya se verá en un tema posterior) que indican qué estructuras hay y qué elementos las componen (cómo es el while, cómo es una definición de variable, etc.). Siguiendo estas reglas, el sintáctico busca esas secuencias de elementos para así identificar las estructuras.
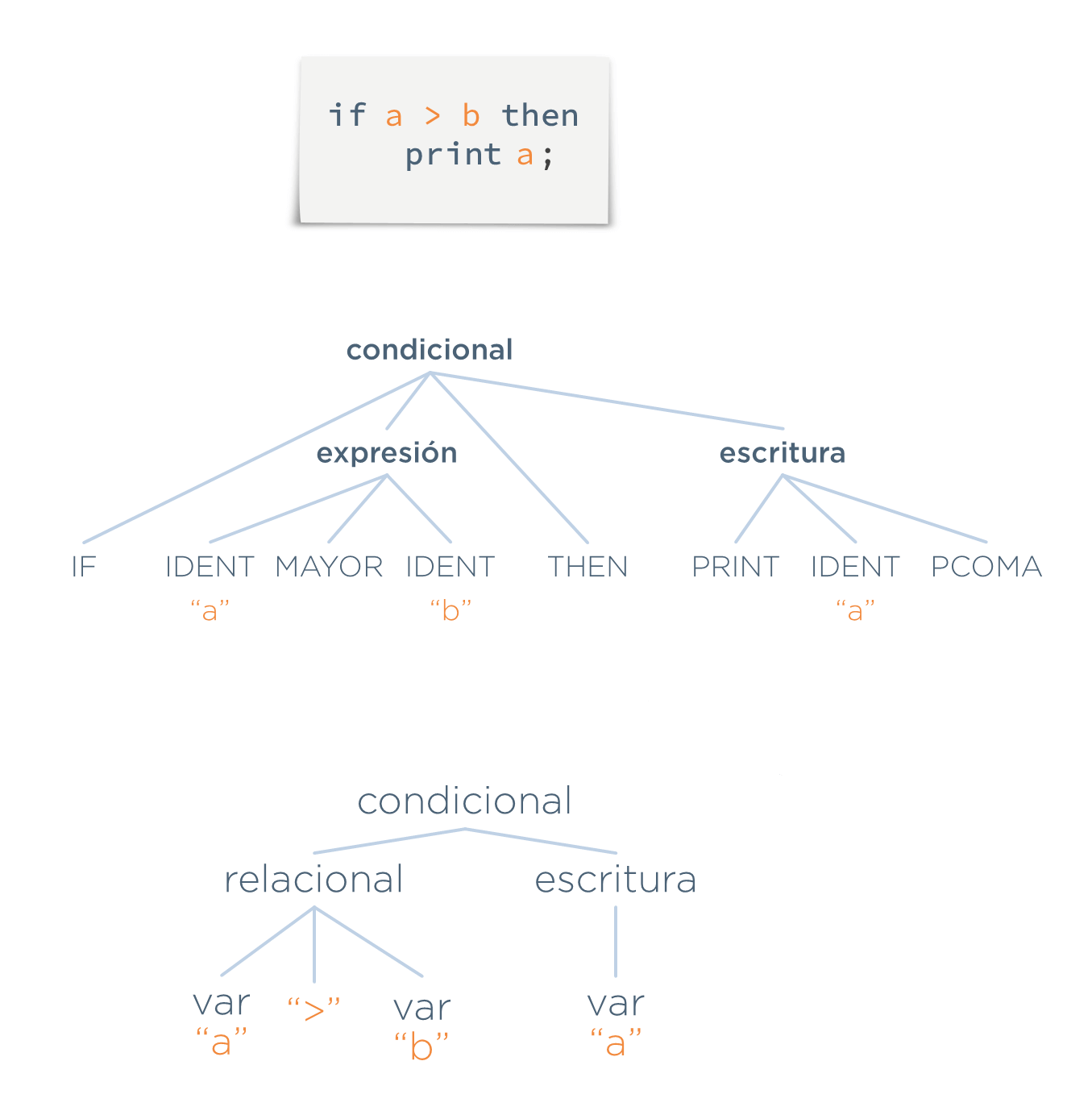
Supónganse definidas unas reglas (las cuales no se muestran para simplificar) que indiquen la estructura de las construcciones condicional (if), expresión y escritura. Supóngase, además, la siguiente entrada:
if a > b then
print a;
Lo que harían el analizador sintáctico, una vez recibidos los tokens (mostrados en la fila inferior de la siguiente imagen), sería encontrar las estructuras resaltadas en negrita encima de los tokens.
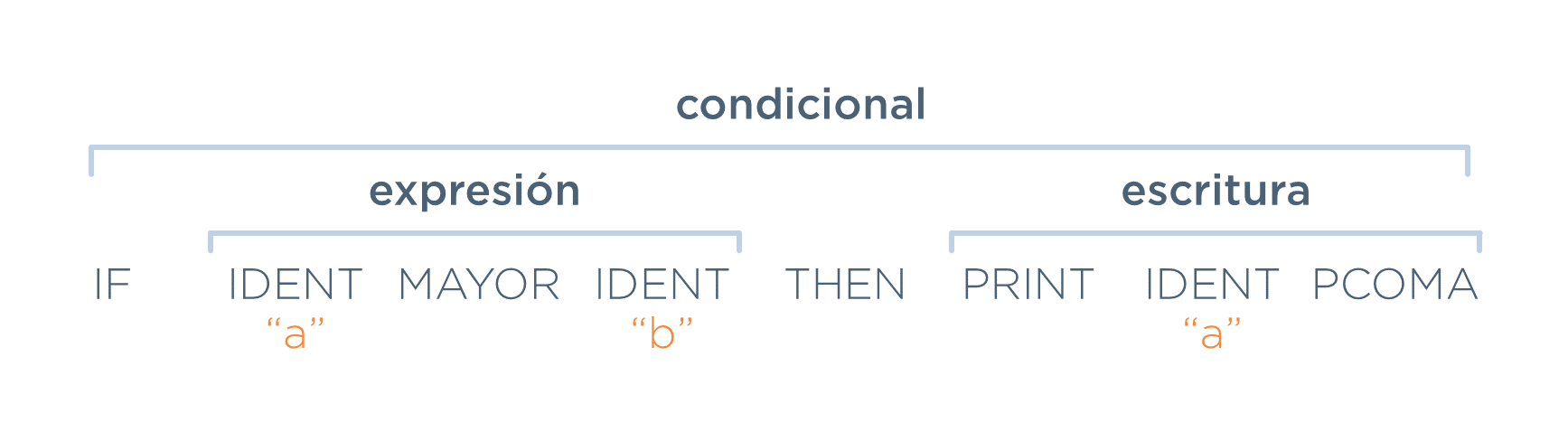
Por tanto, dado que la entrada anterior forma estructuras válidas, la entrada es correcta sintácticamente.
Árbol de Análisis Sintáctico
Queda ahora determinar qué sale del sintáctico, es decir, cómo indica a las demás fases qué estructuras ha encontrado y dónde empieza y acaba cada una.
El analizador sintáctico, durante el proceso de reconocimiento de estructuras, formará un árbol que mostrará la composición del programa analizado. Cada estructura tendrá como hijos a aquellos elementos que la forman. A este árbol es al que se denomina árbol de análisis gramatical. Y en este texto, aunque no sea un término formal, se le llamará árbol concreto por abreviar (en contraposición con el árbol abstracto que luego aparecerá).
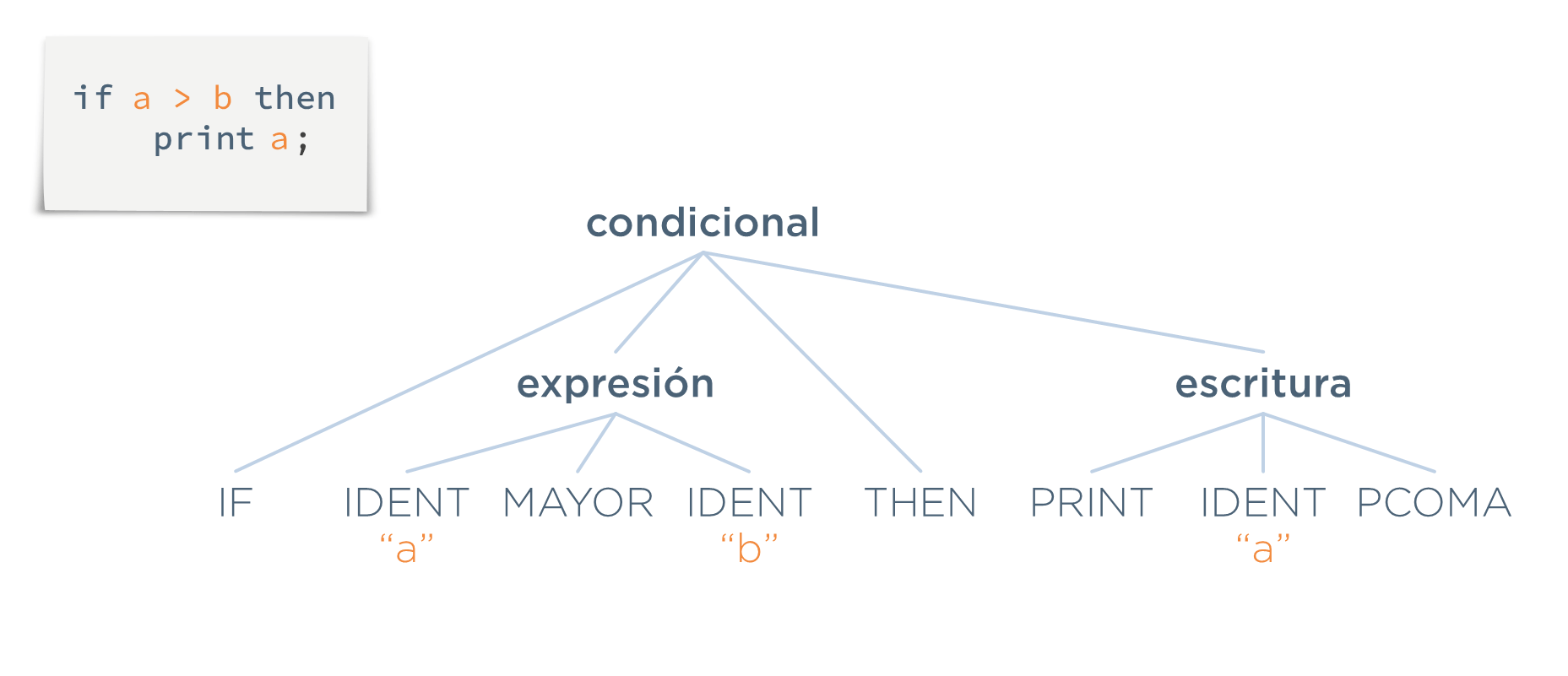
Sin embargo, no es el árbol concreto el que sale del sintáctico. El que sale es un árbol simplificado llamado AST.
Árbol Abstracto (AST)
El Abstract Syntax Tree (AST) o Árbol Abstracto es el árbol mínimo que preserva la semántica de la entrada.
Para decidir qué debería haber es el AST de un lenguaje, una forma práctica para guiarse es plantearse qué es lo mínimo que necesitarían saber el resto de las fases (por ejemplo el Generador de Código) para generar el código destino. Esa información es la única que debería quedar en el AST.
Por ejemplo, aquí se muestra la misma asignación en tres lenguajes de programación distintos (java, pascal, y basic). En cada uno de ellos, el árbol concreto es distinto (porque su sintaxis es distinta).
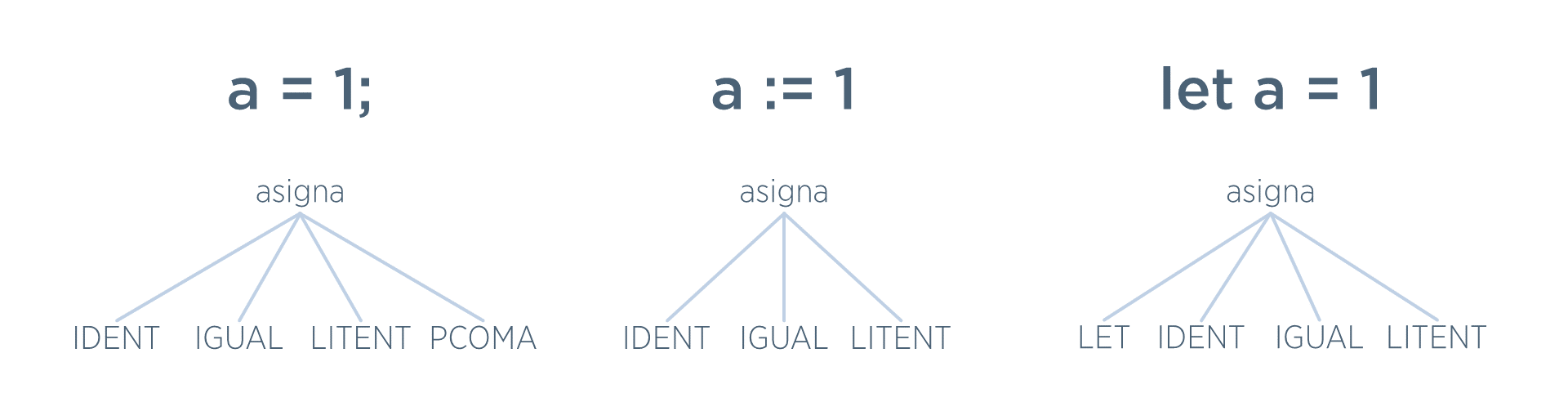
Sin embargo, en los tres casos la información realmente relevante es la misma: a qué variable hay que asignar y qué valor. Realmente es irrelevante para el generador de código si la asignación empezaba por let, si tenía dos puntos o si acababa en punto y coma. Por tanto, el AST sería el mismo en los tres casos.
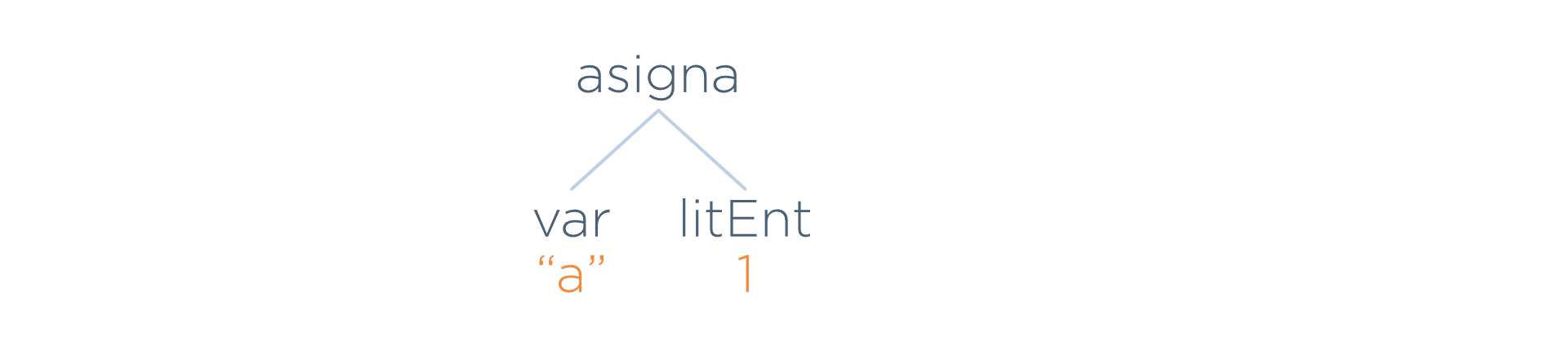
A continuación, se muestran juntos el árbol concreto del ejemplo original y, debajo, el AST que realmente saldría del analizador sintáctico para dicha entrada.
Nótese que el AST no es un subconjunto del árbol concreto:
- Se pueden fusionar, borrar o añadir nuevos nodos. Por ejemplo, se han eliminado los tokens if y then ya que no son necesarios. Estos tokens sirvieron para identificar la construcción condicional, pero, ahora que el nodo raíz ya documenta esa construcción, dichos tokens serían ahora redundantes.
- Al contrario que en un árbol concreto, en un AST los nodos terminales no suelen ser tokens (el nodo var no era un token y, por tanto, no estaba en el árbol concreto).
Por tanto, no debe verse el AST como una transformación del árbol concreto. Se diseña de forma independiente. Crear un AST no consiste en aplicar un algoritmo al árbol concreto para obtener el abstracto. Diseñar el AST es un ejercicio de diseño orientado a objetos: hay que determinar el diseño adecuado para las demás fases del traductor. Esto se verán con más detalle en el tema correspondiente.