Parsers
Qué hace un Parser
Se ha visto anteriormente que una entrada es válida para una gramática G si pertenece al lenguaje que genera dicha gramática L(G), es decir, si se encuentra una serie de transformaciones desde el símbolo inicial hasta dicha entrada.
Este proceso de buscar un camino, que hasta ahora se ha hecho manualmente, se quiere automatizar para que sea realizado por un ordenador. Es decir, ahora, se quiere un algoritmo que reciba:
- Unas reglas en forma de gramática que indiquen qué entradas son válidas.
- Una entrada en forma de tokens.
Y, con lo anterior, encuentre la regla adecuada a usar en cada paso para llegar desde el símbolo inicial a dicha entrada (si existe ese camino).
La aplicación que realiza este proceso se denomina parser.
Tipos de Parsers
Tal y como se ha dicho, un parser busca una combinación de trasformaciones que lleve del símbolo inicial a la cadena. Sin embargo, no hay una única forma de hacer esta tarea. Hay varios algoritmos con distintos grados de compromiso.
- Unos algoritmos son más rápidos para encontrar el camino, pero sólo valen para ciertas GLC. Ejemplo de estos algoritmos son los parsers clásicos LL(1) y LR(1).
- Otros admiten todo tipo de GLC, pero son más lentos a la hora de encontrar el camino. Ejemplo de esto son los parsers CYK, Earley y GLR.
- También hay algoritmos, como packrat, que se basan en otro tipos de gramáticas que no están en la jerarquia de Chomsky llamadas Parsing Expression Grammars (PEG).
- Estos algoritmos, comparándolos con los algoritmos del primer punto, admiten más gramáticas que los algoritmos clásicos LL y LR (a costa de mayor consumo de memoria).
- Y comparándolos con los algoritmos del segundo punto, admiten gramáticas que estos no contemplan y viceversa (no hay una relación de inclusión entre gramáticas PEG y GLC).
Por tanto, antes de usar un determinado algoritmo, hay que asegurarse de que puede aplicarse a la gramática que vaya a implementarse. Cada algoritmo determina cómo deben ser las gramáticas a las que se aplique y esto deberá comprobarse de manera manual o con una herramienta como paso previo a la implementación.
Tradicionalmente, se ha tendido más a usar los algoritmos más rápidos (LL(1) y LR(1)) frente a los más generales. A la hora de realizar un compilador comercial, los usuarios van a comparar los tiempos de compilación con la competencia. Así que, generalmente, era preferible dedicar tiempo para hacer la gramática adecuada para estos algoritmos más restrictivos pero más eficientes y, a cambio, conseguir que luego cada compilación sea más rápida. Al fin y al cabo, la gramática se hace una sola vez y compilar se hará multitud de veces.
Características de los Parsers
Aunque cada algoritmo de los anteriores tendrá sus características particulares, a la hora de describir un algoritmo se suelen utilizar unos términos que es necesario conocer y que ayudan a entender su forma general de trabajar. Estos términos se derivan de cómo trata un parser las siguientes situaciones:
- En qué dirección realiza el reconocimiento de la cadena de entrada.
- Cómo selecciona las reglas a la hora de realizar una transformación.
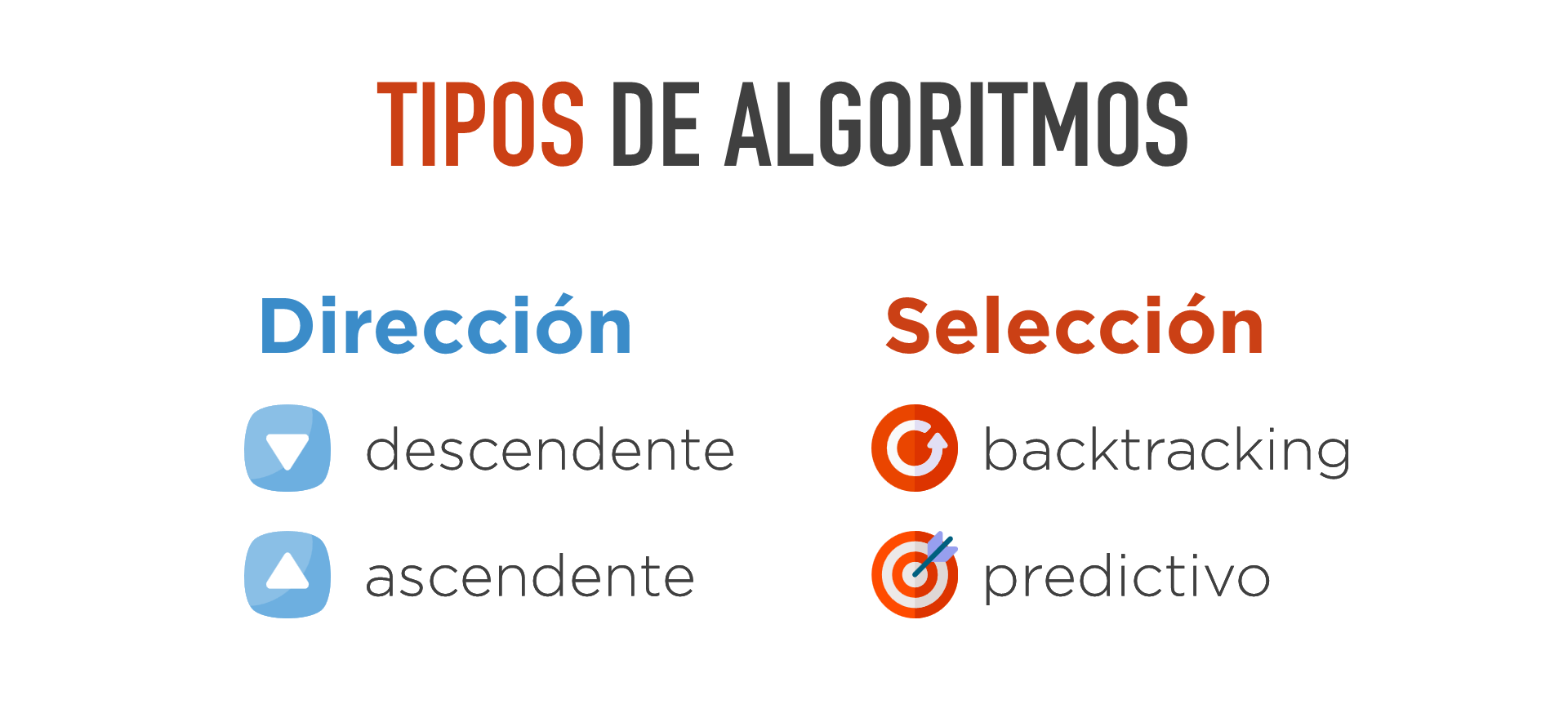
Estas dos clasificaciones son independientes y, por ejemplo, se puede tener un parser descendente y predictivo o otro ascendente y predictivo.
Dirección de Reconocimiento
Según la dirección en la que realizan las transformaciones, los algoritmos se denominan:
- Descendentes. Son aquellos que realizan el proceso a partir del símbolo inicial e intentan llegar a la cadena de entrada (que es como se ha hecho en todos los ejemplos hasta ahora).
- Ascendentes. Son aquellos que realizan el proceso a la inversa. Parten de la cadena de entrada y, haciendo transformaciones a la inversa (es decir, sustituyendo la parte derecha de una regla por la parte izquierda), intentan llegar al símbolo inicial. Estas transformaciones a la inversa es lo que se llaman reducciones.
Por ejemplo, supóngase la siguiente gramática:
s ⟶ A a b E
a ⟶ a B C
a ⟶ B
b ⟶ D
b ⟶ a B C
Se quiere saber si la cadena A B B C D E es válida (es decir, pertenece a L(G)) utilizando un reconocimiento ascendente. Para ello, se obtendría la siguiente secuencia de reducciones:
A B B C D E
⟹ A a B C D E
⟹ A a D E
⟹ A a b E
⟹ s
El nombre de descendente o ascendente vienen por la forma en la que construyen el árbol concreto. En un análisis descendente, como se vio en dicho capítulo, el árbol se construye de la raíz hacia las hojas (hacia abajo). En cambio, si se dibuja el árbol de un análisis ascendente, se puede observar que lo primero que aparecen son los hijos y el árbol aparece hacia arriba.
Selección de Reglas
La segunda forma de clasificar los algoritmos, independientemente de que sean ascendentes o descendentes, es por el criterio que usan para elegir las transformaciones en cada paso del proceso de búsqueda.
Hay situaciones en las que hay varias reglas candidatas a ser aplicadas en una transformación. Supóngase la siguiente GLC:
s ⟶ b D
b ⟶ X c
b ⟶ X b
c ⟶ ε
c ⟶ Y c
Supóngase que la cadena a validar es X X D. Se comienza por el símbolo inicial y se aplica la primera regla para obtener lo siguiente:
s ⟹ b D
Ahora hay que sustituir el no-terminal b. Sin embargo, hay dos reglas que tienen dicho símbolo en su antecedente b ⟶ X c y b ⟶ X b. ¿Cómo sabría el algoritmo cuál de las dos reglas debe aplicar? De hecho, si escoge la primera regla no podría llegar a la cadena final y podría, por tanto, concluir erróneamente que no es válida (cuando sí pertenece a L(G)).
Cuando esto suceda, hay dos tipos principales de parsers: No-Deterministas y Deterministas (o Predictivos). Estos no son los únicos enfoques y, además, puede haber parsers que combinen ambos enfoques en distintos momentos del proceso de análisis.
No-Deterministas (Backtracking)
En este enfoque se elige una de las reglas y, si posteriormente no se llega a la cadena final, se retrocede a un punto en el que se hubiera podido elegir otra regla. Podría decirse que este método es el que nuestro cerebro utiliza inconscientemente cuando, en un ejercicio, se está tratando de averiguar el camino mentalmente.
El problema fundamental de este enfoque es la lentitud. El caso peor es que la entrada no pertenezca al lenguaje y, por tanto, explore multitud de caminos que nunca van a llevar a nada. Y el que la entrada no sea válida, el caso peor, será el más frecuente.
Deterministas o Predictivos
Un parser predictivo, cuando se presente la situación de tener que elegir entre varias reglas candidatas, se asegura de coger la adecuada. Es decir, nunca retrocede. Si no se llega a la cadena, es que ésta no es válida (no es que se haya equivocado de regla en algún punto).
Pero, ¿cómo sabe un algoritmo predictivo qué regla debe coger? Mirando los siguientes tokens que estén en la entrada. Cuando un parser predictivo tiene varias reglas a elegir, mira los tokens y, en función de qué se encuentre, decide qué hacer. Por ejemplo, supóngase esta GLC:
prog ⟶ definición
definición ⟶ clase
definición ⟶ struct
clase ⟶ CLASS IDENT '{' … '}'
enum ⟶ STRUCT IDENT '{' … '}'
Y supóngase la siguiente derivación:
prog ⟹ definición
Ahora se podría sustituir definición tanto por la regla definición ⟶ clase como por definición ⟶ struct. Supóngase que se mira el siguiente token y se encuentra que es CLASS. En ese caso, se podría deducir correctamente que la regla adecuada con la que se debe producir la transformación debe ser definición ⟶ clase (ya que es la única regla en la que sería válido que CLASS fuera el siguiente token). En definitiva, ha bastado con mirar un token de la entrada.
Supóngase ahora la siguiente gramática G:
s ⟶ PRINT a
a ⟶ b
a ⟶ c
b ⟶ IDENT NUM
c ⟶ IDENT IDENT
Y supóngase la siguiente derivación:
s ⟹ PRINT a
Se podría ahora sustituir a tanto por la regla a ⟶ b como por a ⟶ c. Supóngase que se mira el siguiente token y se encuentra un IDENT. En este caso, se seguiría sin saber por cuál de las dos reglas ir. Supóngase ahora que se pide un token más y se obtiene otro IDENT. En ese caso ya sí se podría deducir que la regla adecuada debe ser a ⟶ c. En definitiva, se han tenido que mirar dos tokens de la entrada.
Los algoritmos predictivos son los más comunes (bien en su forma ascendente o descendente) frente a la opción de backtracking debido a su eficiencia.
Clasificación de los Parsers Predictivos
Como se ha visto en el apartado anterior, en función de la gramática, unas veces se necesitan mirar más tokens que en otras para saber qué regla elegir (en uno de los ejemplos anteriores bastó con mirar un token y en el siguiente fue necesario mirar dos). Así, en función de cuantos tokens sea capaz de mirar un parser, se le asigna su nombre.
A un parser que realiza el reconocimiento de manera descendente, se le denomina LL. Los LL también se caracterizan porque realizan siempre la sustitución del símbolo más a la izquierda de la cadena (el primero). Si, además de ser descendente, es predictivo, se le denomina le parser LL(k) donde k es el número máximo de tokens que puede mirar de la entrada. Así, serían parsers LL(k):
- Los parsers LL(1), es decir, aquellos que miran como máximo, un token de la entrada.
- Los parsers LL(2), es decir, aquellos que miran como máximo, dos token de la entrada.
- ...
De manera análoga, se denomina LR a un parser que realiza el reconocimiento de manera ascendente realizando siempre la sustitución del símbolo más a la derecha (el último). Si, además de ascendente, es predictivo, se le denomina parser LR(k), donde k es el número máximo de tokens que puede mirar de la entrada. Ejemplos de parsers LR(k) serían:
- Los parsers LR(1), es decir, aquellos que miran como máximo, un token de la entrada.
- Los parsers LR(2), es decir, aquellos que miran como máximo, dos token de la entrada.
- ...
Clasificación de las Gramáticas
Las gramáticas reciben el nombre directamente del parser con el que pueden ser tratadas, es decir, el mismo nombre de la gramática indica con qué parser se puede implementar y con cuál no. Por ejemplo:
- Se denomina LL(1) a una gramática que puede ser reconocida con un parser LL(1). Es decir, que la gramática puede ser reconocida de manera predictiva (sin backtracking) sin que en ninguna situación vaya a ser necesario mirar más de un token para saber qué regla elegir.
- Se denomina LL(2) a una gramática que puede ser reconocida con un parser LL(2). Es decir, habrá momentos en que se necesite mirar hasta dos tokens para decidir (y, por tanto, no se puede implementar con un parser LL(1)), pero no habrá ninguna situación en la que se necesite mirar tres o más tokens.
- Se denomina LR(1) a una gramática que puede ser reconocida con un parser LR(1). Es decir, de manera predictiva y en dirección ascendente sin que nunca vaya a ser necesario mirar más de un token.
Resumiendo, se llama gramática LL(k) a una gramática que puede ser reconocida con un parser LL(k) y se llama LR(k) a una gramática que puede ser reconocida por un parser LR(k).
Evidentemente, una gramática que sea LL(2), es decir, que no se necesite mirar más de dos tokens para saber qué regla aplicar, podría implementarse con un parser que pudiera mirar tres o más tokens. Por tanto, dicha gramática LL(2) también sería LL(3). Es decir, toda gramática LL(n) también es LL(n+1). Pero se usa como nombre de la misma el del parser, de todos los que pueden implementarla, que mire menos tokens hacia adelante.
En la siguiente diagrama pueden verse los tipos de gramáticas más comunes y las relaciones de inclusión entre ellas. Por lo dicho en el punto anterior, se puede ver que las gramáticas LL(1) están dentro de las LL(k).
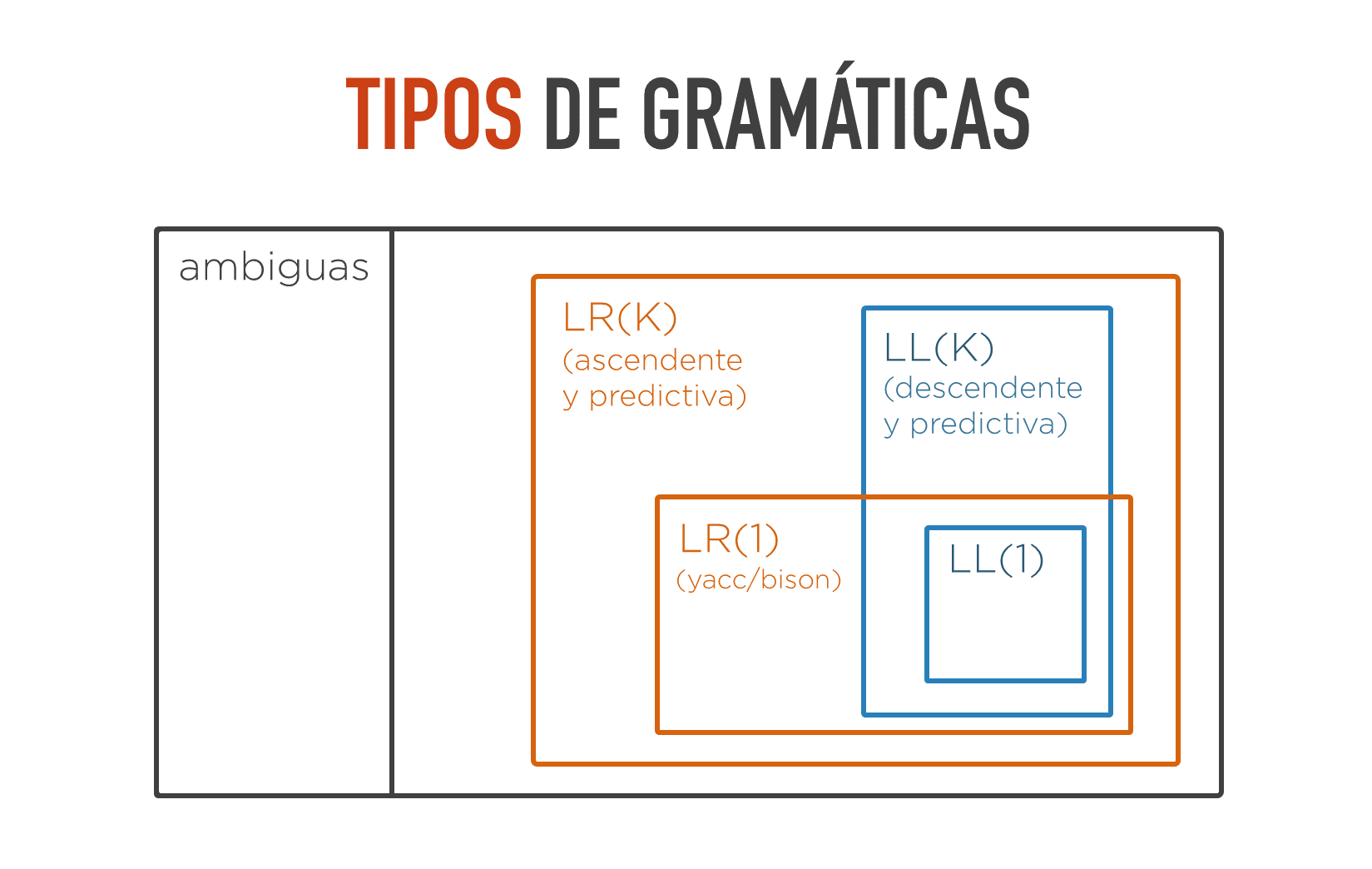
Puede verse en el diagrama que el algoritmo ascendente predictivo es más general que el descendente predictivo. De hecho, toda gramática que pueda reconocerse de manera descendente mirando k tokens, también puede hacerse de manera ascendente mirando el mismo número de tokens (pero el recíproco no es cierto). Es decir, las gramáticas LL(k) son un subconjunto de las LR(k) (por ello las gramáticas LL(1) aparecen como un subconjunto de las LR(1)).
Puede verse, también, que no toda gramática puede implementarse de manera predictiva. Se ve que el conjunto de las LR(k) es menor que el conjunto de las gramáticas no-ambiguas.
Las parser más comunes tradicionalmente han sido los LL(1) y los LR(1) (yacc, Bison, BYaccJ, ...). De hecho, si se tenía una gramática que no fuera adecuadas para ser implementada con estos parsers, lo habitual era transformarla hasta hallar otra gramática equivalente que sí pudiera serlo para beneficiarse de su eficiencia.