Implementación Estructurada
Esta técnica es la más común cuando un léxico se hace a mano, ya que es sencilla y eficiente.
Supóngase la siguiente especificación: 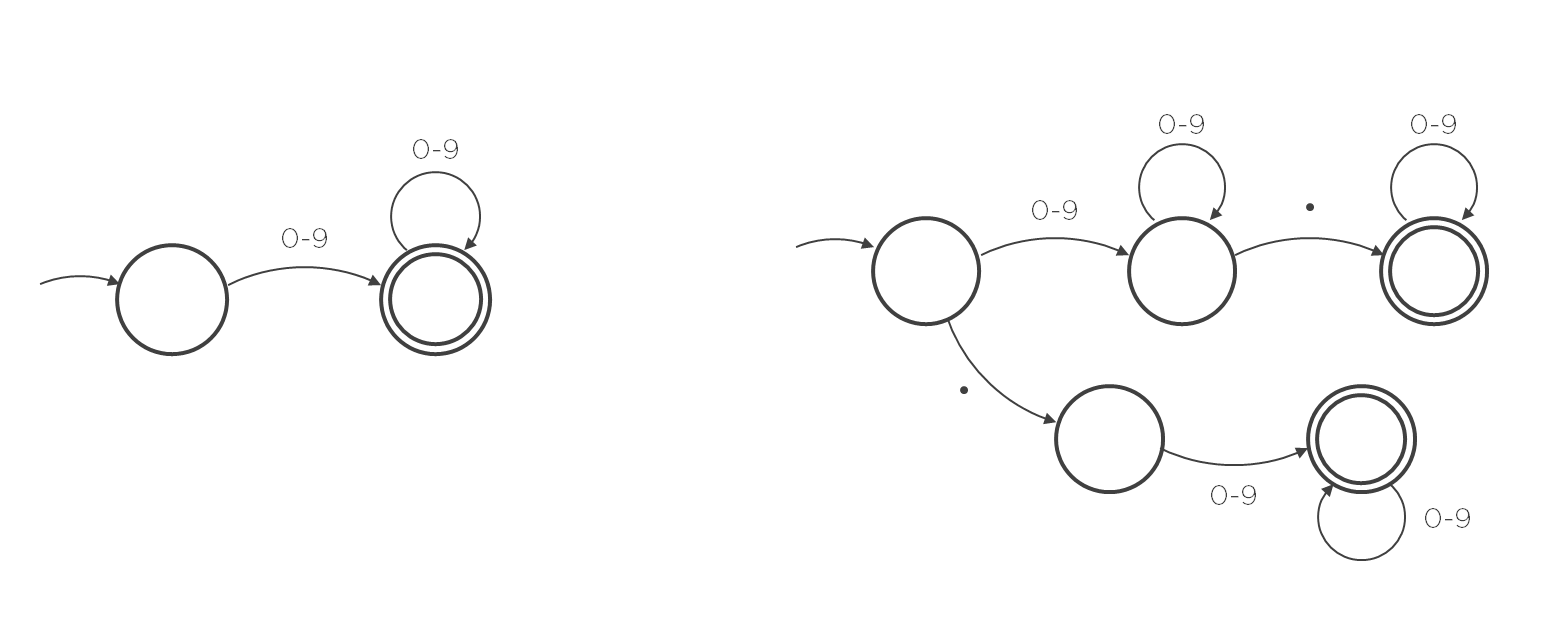
¿Cómo se podría implementar?
- En el autómata de la izquierda, la transición sobre el estado final recuerda a un bucle while.
- En el autómata de la derecha, las transiciones que salen del estado inicial recuerda a la estructura de un if/else (en función del que el carácter a la entrada sea un dígito o un punto, va por un camino u otro).
La técnica estructurada consiste, básicamente, en que cuando los autómatas finitos se asemejan a un ordinograma o diagrama de flujo (cosa que suele cumplirse con los tokens habituales), se consideran como tal y se implementan de la misma manera que estos diagramas.
La forma habitual de implementar los ordinogramas consiste en ir generando, según lo indique el mismo, las construcciones clásicas de los lenguajes de programación: secuencial, alternativa (if) e iteración (while).
Ejemplo 0257
Supóngase la siguiente especificación léxica formada únicamente por dos tokens: LITENT (literales enteros) y la multiplicación '*'.
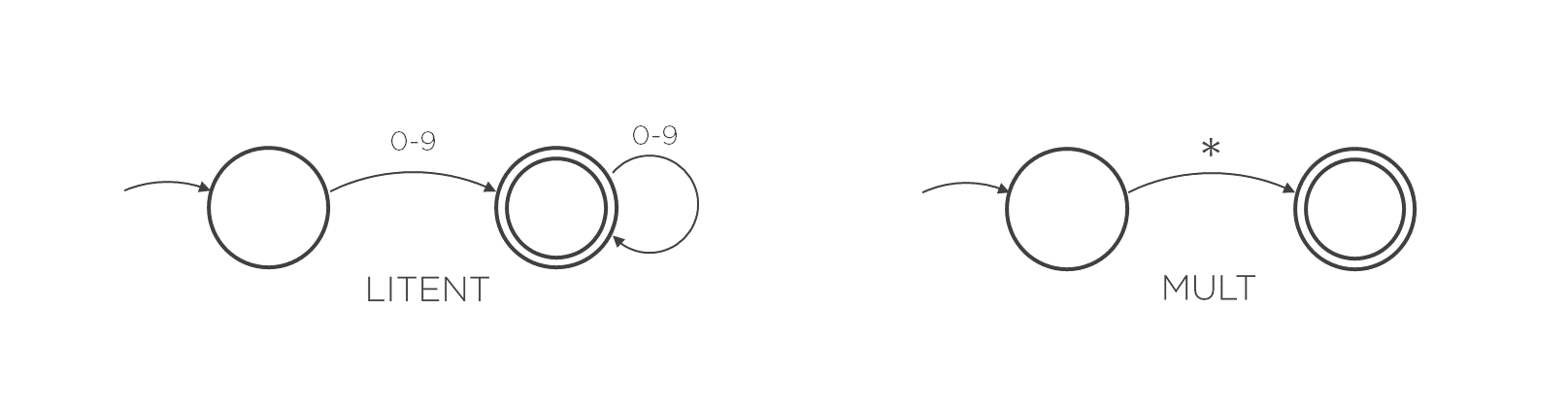
Ahora, hay que realizar la implementación estructurada del método nextToken. Pero antes de ello, hay que crear cierta infraestructura previa.
Se necesita un main que use los valores retornados por nextToken.
var lex = new Lexico(new FileReader("source.txt"));
Token token;
while ((token = lex.nextToken()).getTipo() != Lexico.END) {
System.out.print("Lexema: " + token.getLexema());
System.out.println("\tToken: " + token.getTipo());
}
Siendo el fichero source.txt el siguiente:
24 * 2 * 5
También, como se vio en la implementación de un token, se necesita una clase Token, en la que en este ejemplo se omitirá la información de la posición del lexema (fila y columna) para simplificar.
public class Token {
public Token(int tipo, String lexema) {
this.tipo = tipo;
this.lexema = lexema;
}
public int getTipo() { return tipo; }
public String getLexema() { return lexema; }
private int tipo;
private String lexema;
}
Después se hace la clase Léxico, que es donde se implementará nextToken. En dicha clase se añaden ciertos métodos privados auxiliares (readNext y getChar) para simplificar su implementación.
public class Lexico {
private Reader input;
private int currentChar;
public Lexico(Reader reader) throws IOException {
input = reader;
readNext();
}
// Funciones auxiliares -------------------------------
private int readNext() throws IOException {
currentChar = input.read();
return currentChar;
}
private int getChar() throws IOException {
return currentChar;
}
...
}
La función de cada uno es la siguiente:
- readNext. Cada vez que se llame a este método, devolverá el siguiente carácter del fichero.
- getChar permite ver el carácter actual a la entrada sin pasar al siguiente carácter.
En esta clase, además, hay que definir los valores que se van a devolver con cada token. Para el '*', tal y como se vio en la representación de los tokens, no es necesario definir una constante ya que se utiliza su propio código ASCII. Así que sólo se define una constante para los literales enteros (LITENT) y, como siempre, el valor que indica que no quedan más tokens en la entrada (END).
public class Lexico {
public static final int END = 0;
public static final int LITENT = 256;
...
}
Con toda la infraestructura anterior, ya se puede implementar el método nextToken.
public class Lexico {
public static final int END = 0;
public static final int LITENT = 256;
...
public Token nextToken() throws IOException {
while (true) {
while (Character.isWhitespace(getChar()))
readNext();
if (getChar() == -1)
return new Token(END, null);
if (getChar() == '*') {
readNext();
return new Token('*', "*");
}
if (Character.isDigit(getChar())) {
var buffer = new StringBuffer();
buffer.append((char)getChar());
while (Character.isDigit(readNext()))
buffer.append((char)getChar());
return new Token(LITENT, buffer.toString());
}
System.out.println("Error lexico: " + getChar());
readNext(); // Descartar el error
}
}
}
En el código anterior pueden verse las distintas tareas comunes que debe realizar el analizador léxico:
- Eliminar espacios en blanco tabuladores y saltos de linea. El bucle con isWhiteSpace se encarga de ello.
- Detectar el final de fichero y devolver el token END.
- Comprobar los patrones. El código es la implementación de los autómatas de la multiplicación y de los literales enteros viéndolos como ordinogramas.
- Notificar un error y continuar si no se ha encontrado un lexema válido.
Código
💿 Se puede bajar el proyecto Java con todo lo necesario para poder ejecutar la solución de este ejemplo y así poder ver su resultado y probar otras alternativas.