Implementación con Herramienta
El utilizar una herramienta elimina la parte rutinaria de construir un analizador léxico. En la imagen siguiente, se puede ver la implementación del mismo patrón en su versión manual (izquierda) y su versión con un herramienta (derecha). Lo único que tienen en común es el nombre del token (resaltado en rojo).
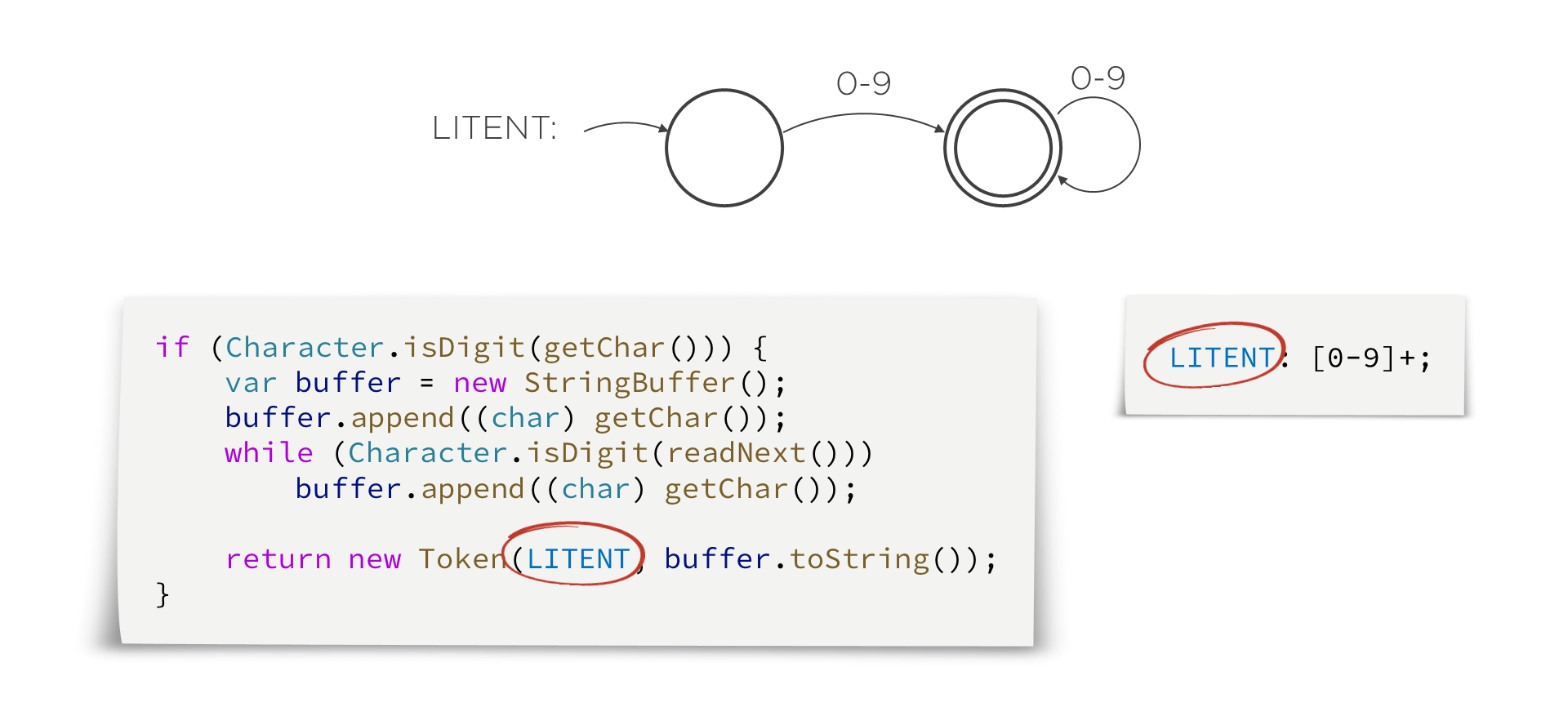
En la versión con herramienta sólo hay que indicar el patrón mediante una expresión regular e indicar a qué token corresponde. La herramienta se encarga de todo el trabajo de procesar los caracteres de entrada, comprobar el patrón y formar el lexema, además de notificar los errores en caso de que la entrada no sea válida.
Las herramientas, en general, utilizan la técnica de Tabla de Estados. Es decir, a partir de los patrones, crean un autómata determinista simplificado. Una vez hecho esto, generan la tabla de estados equivalente y el código que la recorre.
Instalación de ANTLR
En esta asignatura se utilizará la herramienta ANTLR (Another Tool for Language Recognition) en su versión 4, la cual puede usarse tanto para generar analizadores léxicos como sintácticos (esto último se verá en el siguiente capítulo).
Para usar esta herramienta, se tienen dos opciones:
- Bajar el fichero jar de ANTLR y añadirlo de forma manual al entorno de desarrollo que se desee utilizar.
- Usar maven y configurar el proyecto tal y como indica las instrucciones de la página de ANTLR.
También es muy recomendable instalar el plugin de ANTLR correspondiente al entorno de desarrollo que se vaya utilizar.
Uso básico de ANTLR
Una vez añadido ANTLR al proyecto, el primer paso para construir el analizador léxico es entregarle la especificación léxica mediante expresiones regulares.
Como primer ejemplo, se va a construir un analizador léxico de un lenguaje con solo un token: LITENT (literal entero). Para ello, se crea el fichero Lexicon.g4.
// Lexicon.g4
lexer grammar Lexicon;
LITENT: [0-9]+;
WHITESPACE: [ \t\r\n]+ -> skip;
La extensión g4 es un convenio para indicar que es un fichero de ANTLR, pero en realidad se puede poner cualquier extensión.
Una vez hecha la especificación, sólo queda pasarla por la herramienta para que genere el analizador léxico.
java -jar "antlr-4.7.2-complete.jar" -no-listener "Lexicon.g4"
Una vez acabado el proceso, habrá aparecido un nuevo fichero Java llamado Lexicon.java.
c:\ejemplo>dir
Lexicon.g4
Lexicon.java
...
Esta nueva clase es equivalente al analizador léxico hecho a mano. De hecho, incluye:
- Las constantes enteras para los tokens. Para indicar el final de fichero, ANTLR devuelve un token llamado EOF en lugar de END.
- El método nextToken con la implementación de los patrones (concretamente, con el método de Tabla de Estados).
public class Lexicon {
static final int EOF = ...;
static final int LITENT = 256;
...
public Token nextToken() {
...
}
}
Para poder probar dicha clase, solo quedaría implementar el siguiente main.
import org.antlr.v4.runtime.*;
public class Main {
public static void main(String[] args) throws Exception {
var lexer = new Lexicon(CharStreams.fromFileName("source.txt"));
Token token;
while ((token = lexer.nextToken()).getType() != Lexicon.EOF) {
System.out.println("Token: " + token.getType());
System.out.println("Lexema: " + token.getText());
System.out.println("Linea: " + token.getLine());
System.out.println("Columna: " + token.getCharPositionInLine());
}
System.out.println("Traza lexer finalizada");
}
}
Clase Token
A diferencia de la versión manual, con ANTLR no hay que hacer una clase Token, ya que viene hecha con la herramienta. Algunos de los métodos de esta clase son:
| Método | Descripción |
|---|---|
| String getText() | Devuelve el lexema |
| int getType() | Devuelve el token (tipo o categoría del lexema) |
| int getLine() | Devuelve la línea donde estaba el lexema (empieza en 1) |
| int getCharPositionInLine() | Devuelve la columna (empieza en 1) |
El método getType() devuelve un entero que representa el token. Por ejemplo, si la entrada fuera un literal entero, dada la siguiente declaración, devolvería un 256.
public class Lexicon {
static final int LITENT = 256;
...
}
Aunque la clase Token de ANTLR tiene más métodos, en la práctica serán estos los más habituales. Si se desea ver más métodos, se puede usar la documentación del ANTLR.
Nota
📌 A veces, principalmente para trazas o depuración, es útil obtener un string con el nombre del token en vez del número. ANTLR ofrece un método para esto:
lexer.getVocabulary().getDisplayName(token.getType()));
La llamada anterior devolvería un String con el valor "LITENT" en vez del entero 256 que devolvería getType.