Ambigüedad
Definición
En el tema anterior se vio cómo se registraba en un árbol de análisis sintáctico el camino encontrado para llegar desde el símbolo inicial hasta la cadena de entrada (lo cual prueba que es una entrada válida)
Concretamente, se vio esta gramática y un árbol para la entrada que la sigue.
s ⟶ e
e ⟶ e + e
e ⟶ e * e
e ⟶ LITENT
3 + 4 * 5
Sin embargo, existe otra forma de llegar a dicha entrada partiendo de s (y, por tanto, existe otro árbol concreto distinto). Estos son los dos árboles que se pueden obtener para la entrada:
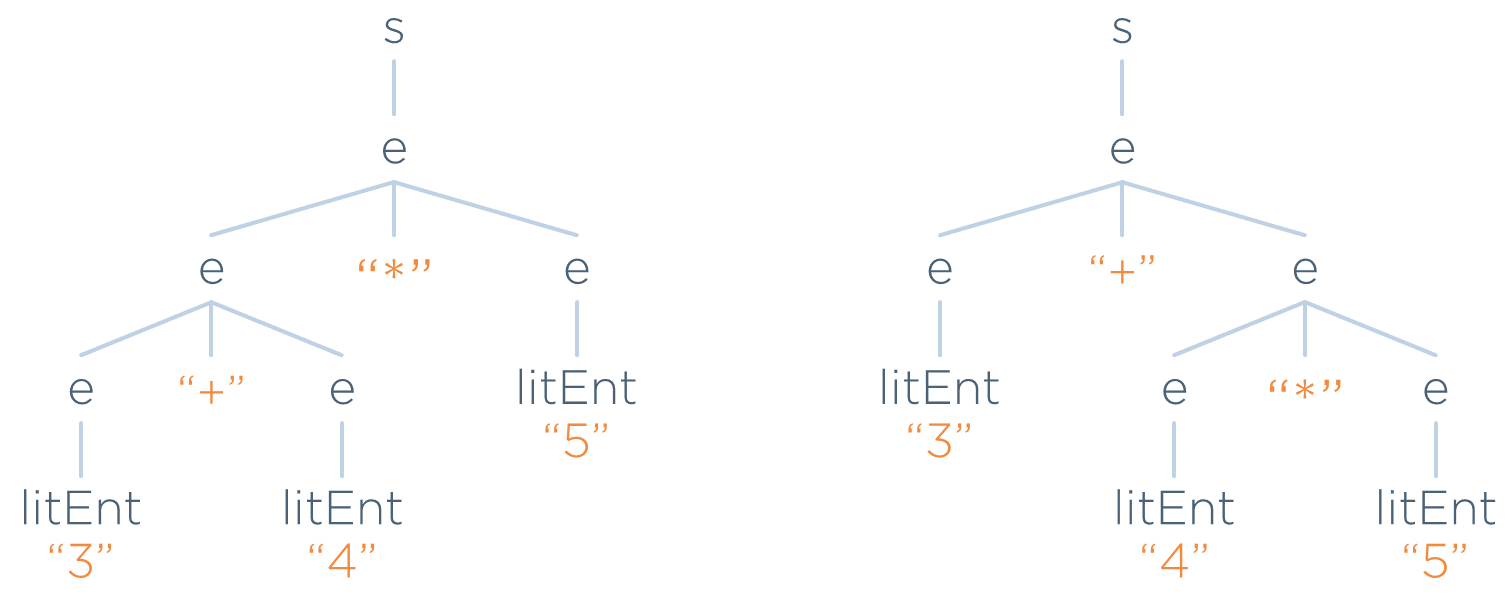
Esto ocurre por que la gramática anterior es ambigua.
Definición
📖 Se dice que una gramática es ambigua cuando existe al menos una sentencia para la que se puede generar más de un árbol de análisis gramatical (es decir, existe mas de una secuencia de transformaciones para llegar a la cadena a partir del símbolo inicial s).
Problema
A la hora de especificar un lenguaje mediante una gramática, la ambigüedad es algo que se debe evitar. Cada árbol supone una interpretación distinta de la entrada. Por ejemplo, en el caso anterior, el árbol de la derecha realizaría la suma antes que el producto (y el resultado de la expresión sería 35) mientras que el árbol de la derecha realiza primero la multiplicación (dando como resultado 23).
Esta situación, en un lenguaje real, supondría que se podría tener un programa que, en función de con qué compilador se generara su código, produciría distintos resultados (en función de qué árbol usara cada compilador para generar el código). Eso haría inservible a dicho lenguaje de programación.
Ahora, una vez establecido que hay que evitar las gramáticas ambiguas, la pregunta es ¿cómo se puede saber si la gramática que se haya creado lo es? El problema es que no existe un algoritmo general que, dada cualquier gramática, determine si es ambigua o no.
Lo único que se tiene es que hay determinados tipos de gramáticas (LL(k) y LR(k)) que se sabe que no son ambiguas. Basta ver el mapa de gramáticas del siguiente apartado para verlo gráficamente. Y el comprobar si una gramática es de alguno de los dos tipos anteriores sí que se puede hacer. Por tanto, lo que se solía hacer tradicionalmente era trabajar con dichas gramáticas y evitar el resto.
En resumen:
- Si una gramática se determina que es LL(k) o LR(k) se sabe que no es ambigua.
- Si una gramática se determina que no es de estos tipos, no se sabe si es ambigua o no (puede que lo sea o que no). Lo único que se podría hacer para demostrar que es ambigua sería encontrar una entrada concreta para esa gramática que tuviera más de un árbol.
Situación
Una gramática ambigua estaría fuera de la zona roja del diagrama.
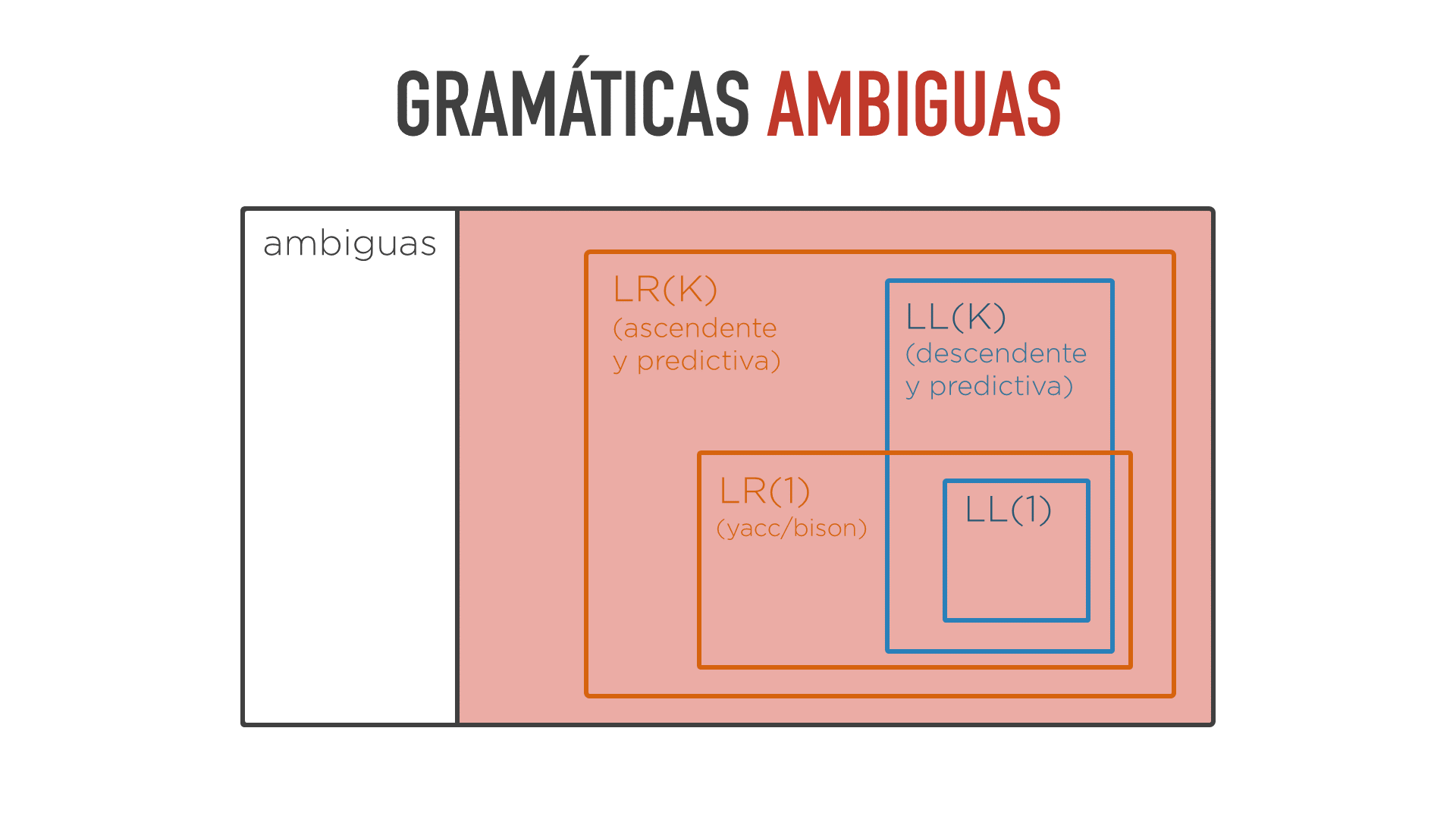
Como puede verse en el mapa, dada la situación de las gramáticas ambiguas en el mismo, en este caso, a diferencia de las dos situaciones anteriores, no será una opción el pasar a utilizar un algoritmo predictivo ascendente.
Posibles Soluciones
Las soluciones más comunes ante una gramática ambigua son:
- Como en las situaciones anteriores, siempre hay la opción de hallar una gramática equivalente.
- Cambiar el lenguaje.
- Usar reglas de selección.
Gramática Equivalente
No existe un algoritmo que, dado una gramática ambigua, genere una que no lo sea. De hecho, existen los lenguajes intrínsecamente ambiguos para los cuales no existe una gramática que no sea ambigua.
Lo que sí hay son soluciones para casos concretos de ambigüedad. Una situación muy común que presenta ambigüedad, y para la qué si hay una solución, es la especificación de la expresiones de un lenguaje de programación. Por ejemplo, ya se vio antes que la siguiente gramática es ambigua:
expr ⟶ expr '+' expr
expr ⟶ expr '*' expr
expr ⟶ LITENT
Para esta situación existe una técnica clásica llamada cascada de precedencias que se usa siempre a la hora de implementar un lenguaje de manera descendente. Esta técnica no se dará por falta de tiempo, pero es interesante al menos comentar su existencia. Si se tiene interés, puede encontrarse en la bibliografía en Construcción de compiladores. Principios y práctica de Louden (página 118).
Básicamente, consiste en separar los operadores por niveles en función de su prioridad (de menos a más) y crear una lista por cada nivel. La gramática anterior quedaría.
expr ⟶ expr '+' termino | termino // lista 1+cs
termino ⟶ termino '*' factor | factor // lista 1+cs
factor ⟶ LITENT
Esta gramática no sería ya ambigua. Sin embargo, para ser además LL(1), habría que eliminar la recursividad a izquierda usando la técnica vista en el capítulo anterior.
La gramática final LL(1) (por tanto, no ambigua y sin recursividad a izquierda) quedaría:
expr ⟶ termino otroTermino
otroTermino ⟶ '+' termino otroTermino | ε
termino ⟶ factor otroFactor
otroFactor ⟶ '*' factor otroFactor | ε
factor ⟶ LITENT
Esta gramática ya sería implementable de manera recursiva descendente.
Expresada en EBNF sería:
expr ⟶ termino ('+' termino otroTermino)*
termino ⟶ factor ('*' factor otroFactor)*
factor ⟶ LITENT
Cambiar el Lenguaje
La solución anterior es una técnica específica para resolver la ambigüedad que se presenta en las expresiones, pero no es, ni mucho menos, una técnica general para resolver la ambigüedad.
Por tanto, puede presentarse una gramática ambigua que:
- O bien la versión no-ambigua sea muy compleja.
- O bien no exista una gramática equivalente que no sea ambigua (lenguaje intrínsecamente ambiguo)
En estos casos, dado que encontrar una gramática no-ambigua para el lenguaje es difícil (o imposible), lo que se puede hacer (si se tiene opción a ello) es cambiar el lenguaje a uno para el que sea más fácil encontrar una gramática adecuada para ser implementada.
Como ejemplo, supóngase la siguiente gramática del if.
sentencia ⟶ if | while | asignacion | ...
if ⟶ IF expr THEN sentencia
| IF expr THEN sentencia ELSE sentencia
Esta gramática es ambigua. Por ejemplo, supóngase la siguiente entrada:
if a > 1 then if b > 1 then print 3 else print 4
Con la gramática anterior, podría interpretarse de dos maneras, en función de a cuál de los dos if se entienda que le corresponde el else.
if a > 1 then
if b > 1 then
print 3
else
print 4
if a > 1 then
if b > 1 then
print 3
else
print 4
Es cierto que el convenio habitual es que el else vaya con el if más cercano, pero esa norma no está integrada en la gramática y el parser, perfectamente, podría encontrar la segunda derivación. Por tanto, la gramática no es válida por ser ambigua.
En este caso, es cierto que existe una gramática equivalente no-ambigua, pero es bastante compleja.
stmt ⟶ matched-stmt | unmatched-stmt
matched-stmt ⟶ IF expr THEN matched-stmt ELSE matched-stmt
matched-stmt ⟶ non-alternative-stmt
unmatched-stmt ⟶ IF expr THEN stmt
unmatched-stmt ⟶ IF expr THEN matched-stmt ELSE unmatched-stmt
Así que se va a optar por la solución de cambiar el lenguaje. Es una solución habitual añadir tokens delimitadores al lenguaje para que fuera sea más fácil obtener una gramática. En el caso del if, el añadir llaves alrededor de las sentencias eliminaba la ambigüedad.
sentencia ⟶ if | while | asignacion | ...
if ⟶ IF expr THEN '{' sentencia '}'
| IF expr THEN '{' sentencia '}' ELSE '{' sentencia '}'
Ahora, sólo hay una forma de reconocer la siguientes entradas:
if a > 1 then { if b > 1 then print 3 } else print 4
if a > 1 then { if b > 1 then print 3 else print 4 }
Muchos de los delimitadores de los lenguajes de programación (los punto y coma al final de las sentencias, las llaves, paréntesis, etc.) tienen origen en situaciones como esta.
Reglas de Selección
Puede darse que las dos soluciones anteriores no sean posible:
- Es difícil o imposible encontrar gramática equivalente.
- No puede cambiarse el lenguaje.
En esa caso, queda el último recurso: las reglas de selección. Una gramática ambigua no es adecuada porque para una misma entrada puede generar varios árboles. El concepto de las reglas de selección consiste en dejar la gramática ambigua pero indicar cuál de los árboles, de entre los posibles, se quiere generar.
No hay una forma general de expresar las reglas de selección de una gramática, ya que el cómo se elige el árbol es específico de cada herramienta.
- En yacc, BYacc y Bison se utilizan las directivas %left y %right.
- En Cup, se usa 'precedence left' y 'precedence right'.
Las reglas de selección deben ser la última opción a la hora de tratar con la ambigüedad. El problema que presentan es que la especificación mediante una GLC ya no es suficiente para saber cómo es la sintaxis del lenguaje, ya que las reglas de selección es una información muy importante que no está reflejada en ella. Por tanto, debe usarse sólo para casos excepcionales. Los casos habituales para usar reglas de selección son las expresiones (para tratar con la prioridad de los operadores) y el caso del if/else anterior.
Qué hace ANTLR
ANTLR acepta gramáticas ambiguas con reglas de selección para indicar qué interpretación se debe hacer de las entradas con más de una interpretación.

ANTLR no podría implementar la primera opción de transformar la gramática, ya que no existe algoritmo que detecte gramáticas ambiguas y menos aún que convierta una ambigua en no ambigua. Tampoco podría cambiar el lenguaje ya que la forma de hacerlo sólo podría ser una decisión del autor del mismo.
La forma de expresar en ANTLR las reglas de selección, a diferencia de las herramientas anteriormente mencionadas, no es mediante directivas de la herramienta. En lugar de eso, las reglas de selección se expresan implícitamente mediante el orden en el que se escriben las reglas. Es decir, en una GLC, por definición, el orden de las reglas no es importante. Sin embargo, en ANTLR, en el caso de existir ambigüedad, el orden de las reglas sí que es importante ya que es a partir de éste de donde deduce las reglas de selección que debe seguir.
Por ejemplo, supóngase la siguiente especificación de ANTLR.
start : 'print' expr ';';
expr : NUM
| IDENT
| expr '+' expr
| expr '*' expr;
Supóngase la entrada:
print 1 + 2 * 3;
Dado que la gramática anterior es ambigua, la entrada podría reconocerse de dos formas: una en que se realiza primero la suma y otra en la que se hace primero la multiplicación.

Sin embargo, ANTLR usar el orden de las reglas para extraer la regla de selección por la cual se quiere elegir el árbol en el que el '+' tiene mayor prioridad. Por tanto, tomaría la interpretación de la izquierda (realiza antes la suma).
Esta, obviamente, no es la que se corresponde con la precedencia real de los operadores aritméticos. La forma de indicarle que se quiere el otro árbol es cambiando el orden de las dos reglas de los operadores '*' y '+'.
start : 'print' expr ';';
expr : NUM
| IDENT
| expr '*' expr;
| expr '+' expr
Ahora, sí que ANTLR interpretaría la entrada de la forma correcta dando más prioridad al '*' y se formaría el árbol de la derecha.
Nota
📌 Hay que resaltar que el orden de las reglas es importante en los casos en los que haya ambigüedad a la hora de interpretar una entrada. En una gramática que no sea ambigua (que es lo que hay que intentar obtener) el orden de las reglas es irrelevante, al igual que lo es en aquellas reglas de una gramática ambigua que no participan de dicha ambigüedad.
Por tanto, sólo en las reglas que producen la ambigüedad es en las que hay que preocuparse del orden (que, en la práctica, suelen ser sólo las de las expresiones).